
はじめに
人工知能については、これまでも「脳型情報処理機械論」の中でも扱ったし、最近ではXAI(ザイ)が注目されていることも投稿した。TED-Ed動画リストを眺めていたらAIの文字が目についたので、今日は次の動画にした。
(出典:YouTube)
人工知能の学習方法
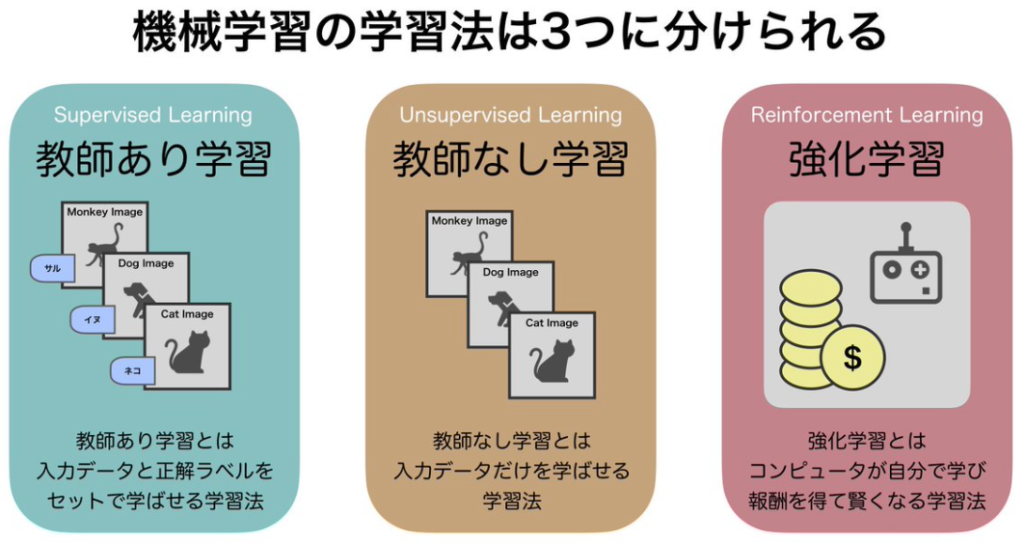
人工知能について事例を交えながら解説し、その3つの学習法についてそれぞれの特徴などを解説している。やはり内容を理解していると英語の動画でも理解はしやすいと感じた。英語力も少しは上がっていると嬉しいけどどうだろう。一般的には次の3つに分類される。
(出典:Twitter)
教師あり
人工知能に写真を見せて、それが何の動物かを判断させたり、マイクロスコープからの写真を見せて癌細胞かどうかを判断させるためには、まずこれは猫、これは犬、これが癌細胞という典型例を覚えさえる方法があり、これを教師ありという。その後も、いろいろな写真を見せて、正解か不正解かのフィードバックを与える中でAIに学習させる方法だ。確実に学習させることができるが、一方でその教えるという作業が必要である。これを改善したのが教師なし学習だ。

(出典:ビジネス+IT)
教師なし
動物は猫と犬だけではない。地球上のあらゆる動物の写真をAIに教え込もうと思っても未知の動物がいるかもしれない。世の中には正解が確定していない問題もある。例えば、新型コロナが蔓延している理由は何か?性別か、年齢か、地域か、嗜好か、行動パターンか。色々な要素が想定されるけど、何が原因かをAIに判断させる方法がある。この場合には、これが原因ですという回答ではなく、要因Aと結果との相関関係の程度とその確らしさを算出することができる。大きく分けてクラスタリングと次元削減がある。クラスタリングとは分類手法だ。ツリーでの分類やマップ上での分類がある。個人的に好きなのはデンドログラムだ。これは以前にも投稿した。一方の次元削減は、人間が理解しやすいようにベクトルを合成する手法だ。要因の数が仮に20だとして、20次元のマップを描いても人間は理解できない。このため、複数の要因からいくつかの主成分を抽出してそれをビジュアルに示すと人間は理解したつもりになる。次元削減については、磯村博士の講義の投稿の中で「エラーゲーテッド・ヘッブの法則(EGHR:error-gated Hebbian rule)を実装したニューラルネットワークは、学習後に経験したすべてのコンテキストの記憶を保持することでマルチコンテキストBSSを実行する。コンテクスト間で低次元のソースを抽出することによる次元削減のためのEGHRの魅力的な利用法を示している。」と説明していた。分かったようなわからないような(笑)。

(出典:楽働)
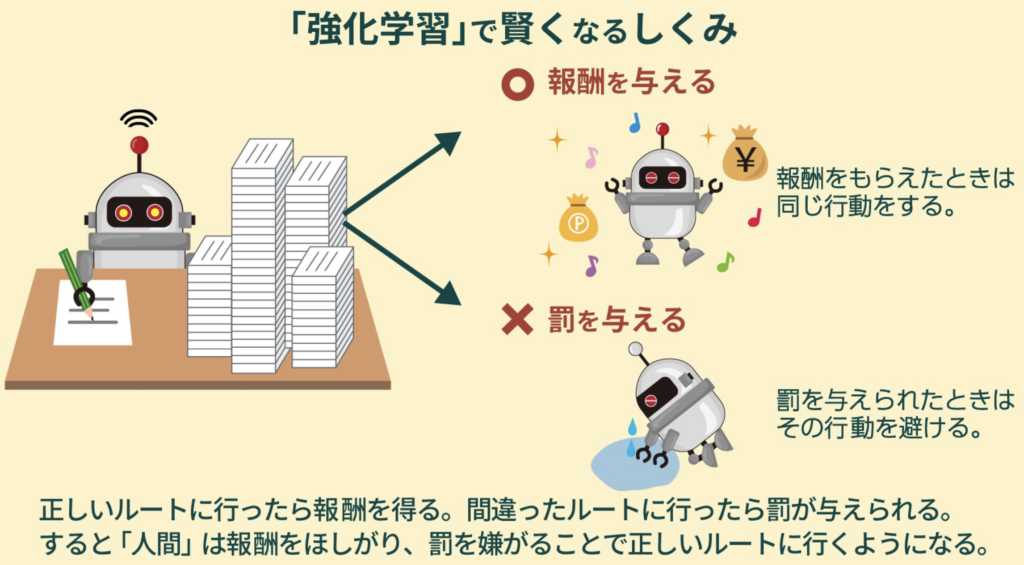
強化学習
褒めて育てるのか、叱って育てるのか。3つ褒めて1つ改善点を指摘するのが良いとあるセミナーで習ったことがある。確かに、3つも褒めてもらうと気持ち良いし、その後の指摘も素直な気持ちで受け入れて改善しようという気持ちになる。これが逆だと辛い。人の場合には、ドーパミンを介してやる気が増加するようだけど、AIの場合にも望ましい処理に報酬を与えると望ましい処理をするようになる。いわゆる躾のプロセスだ。このような考え方で精度を高めているのが強化学習の仕組みであり、囲碁のプロ棋士に勝利したアルファーGOの活躍で注目を集めるようになった。
(出典:ビジネス+IT)
7つの質問
Q1) How does supervised machine learning figure out what rules to follow to do a task?
教師あり機械学習はどのようなルールに従ってタスクを実行するのか、どのように把握するのかという設問だ。データサイエンティストがルールを学習し、コンピュータが従うようにプログラミングする必要があるので次のような感じあろうか。
Q2) Supervised learning is:
教師あり学習とはという設問だ。データサイエンティストが分類タスクの正解を知っていて、それを使ってAIに新しいデータポイントの分類方法を自力で学習させる方法なので、次のような感じかなあ。
Q3) Unsupervised learning is:
教師なし学習とは何かという設問なので、AIが何を探すべきか事前に知ることなく、データのパターンを見つけることを可能にする一連の学習手法なので、次のような感じか。
Q4) Reinforcement learning is:
強化学習とはという設問なので、ゴールを知ってゲームをする戦略を立てるのに使われる学習手法なので、次のような感じか。
Q5) Which of the following is NOT true?
複数の選択肢が用意されていて、誤っているものを選択する設問だ。「人工ニューラルネットワークは、顔の認識にのみ使用できる(Artificial neural networks can only be used to recognize faces)」は誤りだ。
Q6) What is the advantage of using machine learning over rules-based methods for doing tasks like classifying types of fruit?
果物の種類を分類するような作業で、ルールベースではなく機械学習を使うメリットは何かという設問だ。ルールベースは1990年台のAIの時代に脚光を浴びた手法で処理が確実だけど、そのルールを作るのが大変。一方、機械学習では、大量のデータがあれば、それで自己学習させたり、一定の指導をしながら学習させたり、正しい処理の時に報酬を与えることで自己学習を強化できる。特に果物の分類であれば、教師なし学習で客観的に整理できる点が強みだろう。解答を考えた時には、設問の趣旨を誤解していて、次のような回答にしたが、これでは点数にならない(涙)。
Q7) What type of machine learning might be useful for deciding whether a picture is a cat or a dog? What information would you need to do this?
ある写真が猫か犬かを判断するためには、どのような機械学習が有効か。そのために必要な情報は何かという設問だ。以前は、教師あり学習が、写真が猫か犬かを見分けるのに有効でしたが、現在では、膨大な数の猫や犬の写真を使うことができれば、教師なし学習が有効なので、次のような感じか。
将来期待される技術
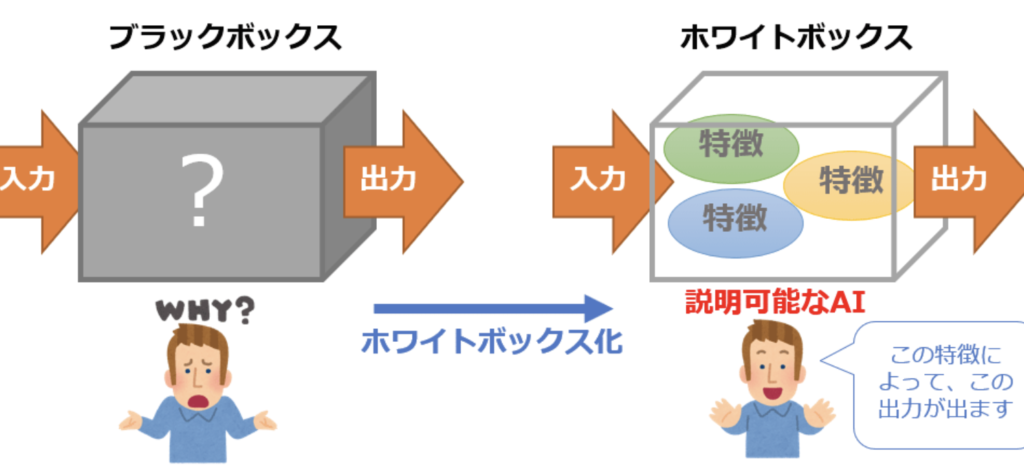
人工知能の最大の欠点は、なぜその答えが導き出されたかを明確に説明できない点だ。これだと説明責任を求められる分野では使えない。なぜならAIは単なるツールであり、そのツールを活用する人間が答えの良し悪しを判断する必要があるが、ブラックボックスの処理で答えだけ出されても、納得できないし、他の人にその理由を説明できなければ、その人は責任を全うしたことにはならない。このため、現在、開発が進められているのが、説明可能な人工知能(XAI)だ。ザイと呼ぶ。これができれば、例えば、新型コロナ対策の抑制策として、飲食店を20時で閉鎖することは有効かという設問に対して、◯◯の理由から有効だとか、△△の理由から有効とは言えないなどの結論とその理由を示すことができれば、国民も納得しやすいだろう。しかし、A社の人工知能と、B社の人工知能では同じ設問でも異なる回答や理由になる可能性は十分にあり、判断を下す場合には複数のシステムを活用して、その処理の妥当性を判断することも同時に求められるだろう。
(出典:AI&Machine Learning)
まとめ
今回は、AIに関する動画を視聴した。わかりやすく説明しているのはさすがだと思う。自分が得意な分野の英語を数多く聞くことも英語能力の向上には有効かもしれないけど、TOEFLでは不得意な科目や分野の題材もあり得るので、やはり情報は広く集めて、研鑽を継続することが大事かもしれない。
以上
最後まで読んで頂きありがとうございました。
拝
参考:英文スクリプト
Today, artificial intelligence helps doctors diagnose patients, pilots fly commercial aircraft, and city planners predict traffic. But no matter what these AIs are doing, the computer scientists who designed them likely don’t know exactly how they are doing it. This is because artificial intelligence is often self-taught, working off a simple set of instructions to create a unique array of rules and strategies. So how exactly does a machine learn? There are many different ways to build self-teaching programs. But they all rely on the three basic types of machine learning: unsupervised learning, supervised learning, and reinforcement learning. To see these in action, let’s imagine researchers are trying to pull information from a set of medical data containing thousands of patient profiles.
First up, unsupervised learning(教師なし学習). This approach would be ideal for analyzing all the profiles to find general similarities and useful patterns. Maybe certain patients have similar disease presentations, or perhaps a treatment produces specific sets of side effects. This brad pattern-seeking approach can be used to identify similarities between patient profiles and find emerging patterns, all without human guidance. But let’s imagine doctors are looking for something more specific. These physicians want to create an algorithm for diagnosing a particular condition. They begin by collecting two sets of data – medical images and test results from both healthy patients and those diagnosed with the condition. Then, they input this data into a program designed to identify features shared by sick patients but not healthy patients. Based on how frequently it sees certain features, the program will assign value to those features’ diagnostic significance, generating an algorithm for diagnosing future patients. However, unlike unsupervised learning, doctors and computer scientists have an active role in what happens next. Doctors will make the final diagnosis and check the accuracy of the algorithm’s prediction. Then computer scientists can use the updated datasets to adjust the program’s parameters and improve its accuracy. This hand-on approach is called supervised learning(教師あり学習).
Now, let’s say these doctors want to design another algorithm to recommend treatment plans. Since these plans will be implemented in stages, and they may change depending on each individual’s response to treatments, the doctors decide to use reinforcement learning(強化学習). This program uses an iterative approach to gather feedback about which medications, dosages(投与量), and treatments are most effective. Then, it compares that data against each patient’s profile to create their unique, optimal treatment plan. As the treatments progress and the program receives more feedback, it can constantly update the plan for each patient.
None of these three techniques are inherently smarter than any other. While some require more or less human intervention, they all have their own strengths and weaknesses which makes them best suited for certain tasks. However, by using them together, researchers can build complex AI systems, where individual programs can supervise and teach each other. For example, when our unsupervised learning program finds groups of patients that are similar, it could send that data to a connected supervised learning program. That program could then incorporate this information into its predictions. Or perhaps dozens of reinforcement learning programs might simulate potential patient outcomes to collect feedback about different treatment plans. There are numerous ways to create these machine-learning systems, and perhaps the most promising models are those that mimic(真似る) the relationship between neurons in the brain.
These artificial neural networks can use millions of connections to tackle difficult tasks like image recognition, speech recognition, and even language translation. However, the more self-directed these models become, the harder it is for computer scientists to determine how these self-taught algorithms arrive at their solution. Researchers are already looking at ways to make machine learning more transparent. But as AI becomes more involved in our everyday lives, these enigmatic decisions have increasingly large impacts on our work, health, and safety. So as machines continue learning to investigate, negotiate and communicate, we must also consider how to teach them to teach each other to operate ethically(倫理的に).


