
はじめに
ユーザのためのAI入門の第二回の講義を本日受講した。第一回の講義については、すでに投稿した。今回は東京大学の原田教授をゲスト講師として特に「深層学習時代のAI」というタイトルで講義をして頂いた。昨年度受講した「脳型情報処理機械論」の講義と異なり、基本的に講義は日本語なのが助かる。ただ、利用された資料はほとんどが英語ベースだった。やはり最新情報は英語ベースなのだろう。今回は次の3回に分けて投稿する。なお、この投稿は講義の受講メモではない。あくまで受講して感じたことをネットで確認しながらまとめたものなので、もし問題があればその文責は自分にあるし、内容が興味深いものであれば原田教授のおかげです。
その1:ゲスト講師である原田達也教授の紹介と研究分野(→ 今回の投稿)
その2:深層ニューラルネット(Deep Neural Network:次回の投稿)
その3:ビッグデータの処理(Large Aboiunt of Data processing:次々回の投稿)
ゲスト講師
今回のゲスト講師は東京大学先端科学技術研究センターの原田達也教授だ。2001年に東京大学大学院工学系研究科博士課程を修了し、工学の博士を取得される。2001年には、カーネギーメロン大学の客員研究員、東京大学大学院情報理工学系研究科の助手となられる。2006年には、東京大学大学院情報理工学系講師、2009年には同准教授を経て、2013年には同教授に就任される。理化学研究所確信知能統合研究センターチームリーダ、国立情報学研究所医療ビッグデータ研究センター客員教授を兼任し、2019年9月より現職であり、深層学習によるAI研究などの最前線を牽引されている。

(出典:ロボスタ)
研究テーマ
原田教授の研究テーマは、実世界から有益な情報を抽出し、サイバー空間の膨大なデータと強力なコンピューティング能力と結びつけ、計算機をはじめとした機械のための高度な知能システムの構築を目指されている。この問題に切り込むために数理基盤やロボティクスを含むコンピュータサイエンス全般を活用して研究を進められている。数理基盤では、情報理論、機械学習、深層学習、データマイニング、パターン認識、特徴抽出理論、因果解析、統計的学習理論を、認識・理解・思考では画像認識、自然言語処理、音声・音楽情報処理、行動認識、マルチモーダル認識、コンピュータビジョン、三次元情報処理、検索、対話理解、感情理解、画像・動画の自然言語記述と要約、面白さの発見を、そして生成では画像生成、音楽生成、ロボットの行動生成、対話システム、記事生成などを研究テーマとされている。
ジャーナリストロボット
原田教授が情報理工学の准教授の頃、國吉教授と共にジャーナルロボット(JR)を研究されていた。JRは、身の回りで起きる事象を発見して、ニュース性があると判断した場合には、自動で記事を生成する自律行動型のロボットだという。JRは、自分の現在位置を計算し、ニュース制のある出来事を検出したら、実際に現地を訪問して、調査を行う。また、合成音声に基づいてインタビューを行う自律行動システムや、移動体の自己位置情報を利用した画像からの異常領域検出といった技術が利用されている。これらを応用すれば、警備用ロボットとしての利用や、自動運転ロボットへの応用なども考えられるという。

(出典:InternetWatch)
人工知能ゴーグル
これは、原田教授が東京大学大学院情報理工学系講師だった2008年ごろの研究だ。ヘッドマウントディスプレイ(HMD)を備えたゴーグルと小型カメラ、タブレットPCで構成する。例えば、玄関の鍵を探したい時には、部屋の様子をカメラで撮影し、カメラで撮影されたものを机とか、壁とか、テレビとかと認識する。そして、玄関の鍵を撮影すると、それが鍵と認識され、ディスプレイに表示される。iPhoneが日本で初めて売り出されたのが2008年であり、この当時にこのような研究をされていたのは初めて知った。このシステムでは、カメラで撮影したものを文字として表示することで思い出しを支援する。コンピュータやデバイスの技術革新は進んでいる。スマートグラスが本格的に活用される時代も近いのでは無いだろうか。

(出典:東京大学先端科学技術研究センター)
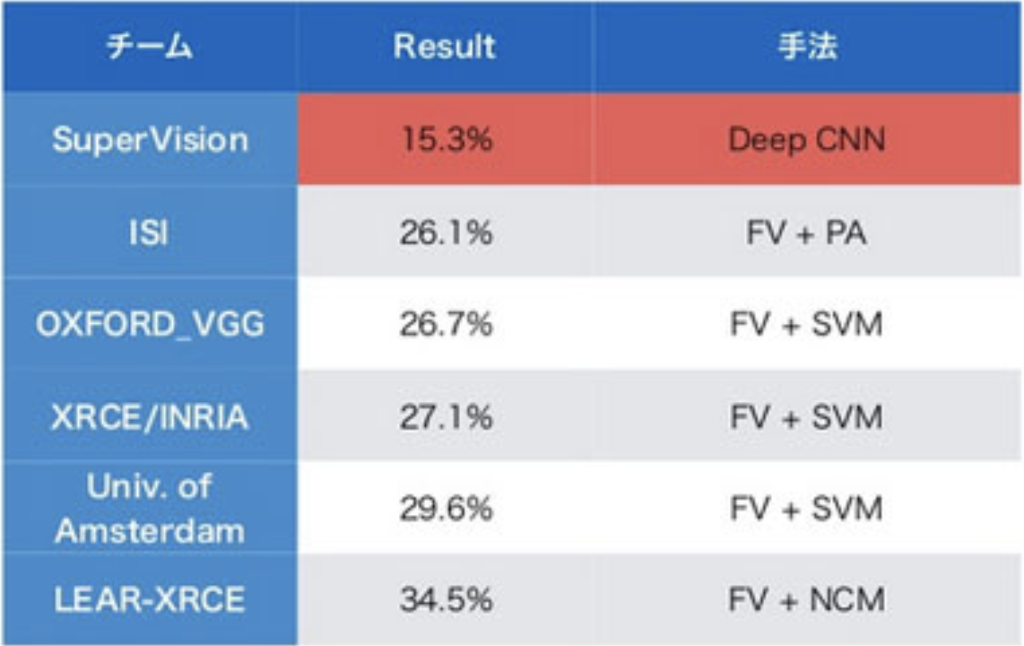
ILSVRC2012での画像認識研究発表
2012年9月2日に開催されたImageNet Large Scale Visual Recognition Challenge 2012(ILSVRC2012)では、1000万以上のラベル付き画像のサブセットをトレーニングとして用い、検索や自動アノテーションのために写真の認証精度を競うコンテストだ。次のような3つのタスクに分かれていた。
タスク1: 写真の認識
・120万枚の画像をもとに、1000のオブジェクトクラスに分類する。
タスク2:写真のロケーションの分類
・1000のオブジェクトクラスを検出する。
タスク3:きめ細かな種類の検出
・犬を120のきめ細かな種類に分類する。
2012年に開催されたコンテストで原田教授(当時は准教授)が率いるチームはタスク1で準優勝、タスク3で優勝という快挙を果たされた。ただ、このコンテストのタスク1で優勝したのが、ジェフリー・ヒントン(1947年12月6日生)教授が率いるトロント大学のSuperVisionのDeep CNNだった。ヒントン教授は、今もトロント大学で研究を続けならが、Googleでも活躍されている。ヒントン教授はニューラルネットワークのバックプロパゲーション、ボルツマンマシン、オートエンコーダ、ディープ・ビリーフ・ネットワークの開発者の1人であり、オートエンコーダやディープ・ビリーフ・ネットワークはディープラーニングになり、その後の深層学習ブームの火付け役となった。
(出典:ITMedia)
ルービックキューブを解決するロボット
講義の状況は次回の投稿に回すが、最初に五本の指をもつ片手のロボットが器用にルービックキュービクルを操作して、鮮やかに6面を綺麗にしていた。もうこのようなことも可能となっている時代だと少しショックを受けた。その様子を動画で視聴することができる。興味のある人は視聴してみてほしい。
(出典:YouTube)
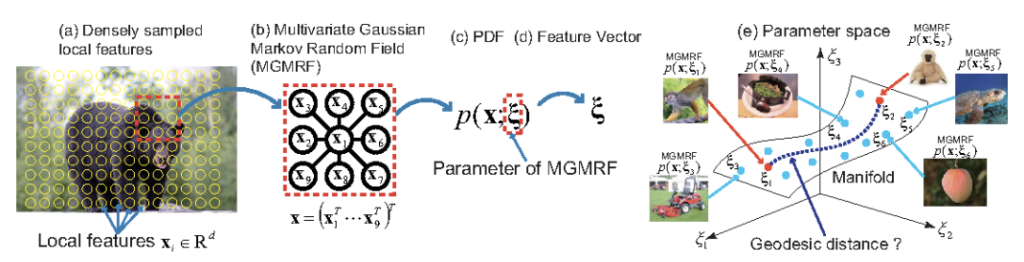
Graphical Gaussian Vector
原田教授が2012年に発表されたペーパーのひとつだ。本論文では、コードブックや局所特徴量照合のアプローチに対応するグラフィカルガウスベクトル(GGV:Graphical Gaussian Vector)と呼ばれる新しい画像表現を提案している。難解だけど、局所特徴の分布をガウス型マルコフ確率場(GMRF:Gaussian Markov Random Field)としてモデル化し、局所特徴間の空間的関係を効率的に表現している。情報幾何学の概念を用いると、GMRFから適切なパラメータとメトリックを得ることができるという。そして、パラメータに適切なメトリックを埋め込むことにより、新しい画像特徴を定義し、これをスケーラブルな線形分類器に直接適用することができる。GGVは、標準的な物体認識データセットにおいて最先端の手法よりも優れた性能を示し、シーンデータセットにおいても同程度の性能を得ることができるという。自分が奈良高専の5年生だった1977年には印鑑の自動照合の研究を行った。当時は学校の計算能力も貧弱だったので、特徴点を抽出して、それをマッチングするという簡便な方法だったけど、このGGVなどを使えばもっと精緻に照合ができるのでは無いかと思った。
(出典:T. Harada)
まとめ
毎週水曜日の夕方16時50分から19時35分までの講義だ。今日は、打ち合わせが長引いてしまって、最初の10分ほどを聞くことができなかったけど、テキストや動画を再生して視聴できるのは助かる。また、10年前に開催された画像認識に関するコンテストで優秀な成績を果たしたが、その時の優勝者が提唱した深層学習の仕組みがその後の10年の火付け役となる現場を肌で感じたことは研究者としての第二の出発点となったたのでは無いだろうかと思った。次回は、この深層学習を中心とした各種ツールの最善線について触れて行きたい。
以上
最後まで読んで頂きありがとうございました。
拝
(参考)
その2:深層ニューラルネット(Deep Neural Network:次回の投稿)
その3:ビッグデータの処理(Large Aboiunt of Data processing:次々回の投稿)


