
はじめに
ユーザのためのAI入門の第二回の講義を13日に受講した。その1ではそのゲスト講師である原田教授や研究分野などを紹介した。今回のその2では、講義の内容の中でも特に深層ニューラルネットを中心に講義で説明された内容をネットで裏取りしながら理解した範疇でまとめてみた。次回のその3ではいわゆるビッグデータの処理関連についてまとめたい。つまり次の3回に分けて投稿する。
その1:ゲスト講師である原田達也教授の紹介と研究分野(前回の投稿)
その2:深層ニューラルネット(Deep Neural Network ⇨ 今回の投稿)
その3:ビッグデータの処理(Large Aboiunt of Data processing:次回の投稿)
Deep Neural Network
AlphaFold2
講義の最初に説明があったのは、タンパク質の構造予測を実行する人工知能プログラムであるAlphaFold(アルファフォールド)2だ。これは、Googleが提供するDeepMindによって開発されたプログラムであり、タンパク質の折り畳み構造を原子の幅に合わせて予測する深層学習システムだ。AlphaFold2は2018年にリリースされたAlphaFoldの第2世代として2021年にGitHubで無償公開されている。生物学、薬学、化学、計算科学などに関わる幅広い領域の研究者が注目して活用している。ゲノムシーケンスデータから塩基配列だけがわかっているタンパク質について、アミノ酸の一次配列からタンパク質の構造と機能を推定したいと言った要望や、タンパク質の結晶構造を決めるために結晶を作って回折像を得たものの、位相が決定できずに途中で解析がお蔵入りしていているが予測構造を活用して構造解析をやり遂げたいと言った意見、タンパク質同士がどんな複合体を形成するかのシミュレーションをやりたいと言った声が続々と集まっているという。
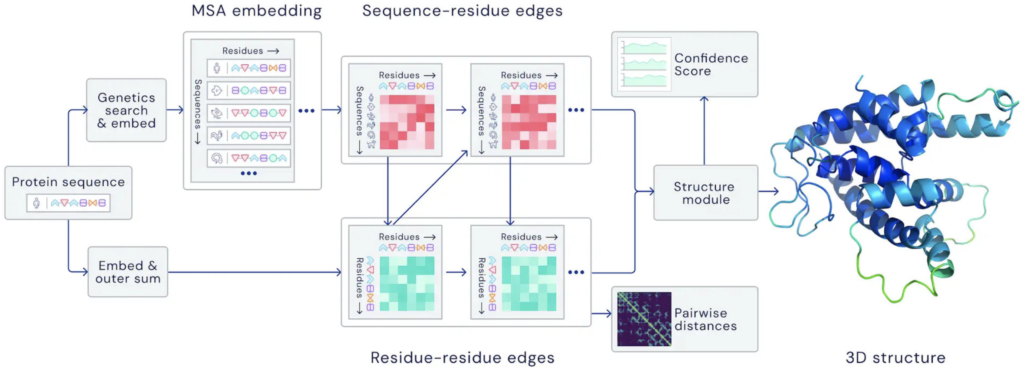
(出典:ITMedia)
Large Scale Visual Recognition Challenge(ILSVRC)
原田教授率いる東大チームが2位となったのが2012年だ。当時優勝したトロント大学のエラー率は15.3%だった。2010年の28%から比べると約半分に減少した。そして、画像照合の誤り率は、年々低下し、2015年には人間の誤り率と言われる5%をクリアし、2017年には2,3%まで低下している。毎年3割減のパターンが今も続いるとすると、2022年の誤り率は、0.55%、2030年には0.03%となる。自動運転の安全度係数をどこまで見るかは、この自動認識の誤り率をどこまで許容するかという問題と同義だと思う。誤り率がゼロ%というのはあり得ない。人間の5%より低ければ良いのでは無いかというのは多分社会的に許容されないが、では人間に比べてどこまで少なければ良いかというと答えは出しにく。しかし、個人的には、2022年で仮に0.55%と1%を切っているなら試行的サービスを始めて、知見を蓄積させることに舵を切るべきタイミングだと思う。誤り率の低下は、機器の性能向上に伴い必然的に低下するが、それ以上に重要なことは知見を増やすことだ。また、その知見を全ての自動車で共有することだ。100万台、1000万台、一億台の自動車が日々画像認識をして、そこで発生した誤りを全ての自動運転車の教訓として活用することができれば、社会全体としての誤り率は指数関数的に減少するだろう。例えば、どこかで水道工事のため路肩を工事している。どこかの道路でオイルが漏れてしまった。どこかに保育園ができて母子乗りの自転車走行が増えている。そういった日々の情報を蓄積し、共有し、活用することが可能となれば、手動運転よりも自動運転が格段に安全で安心という世界に近づくと思う。
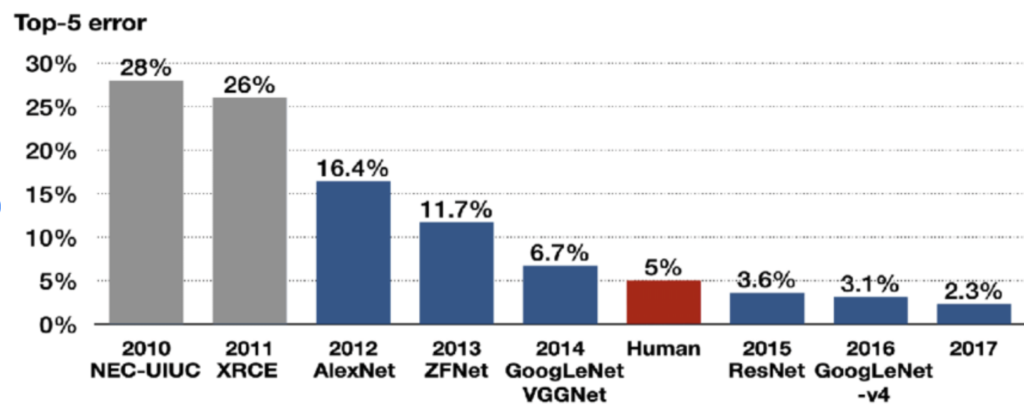
(出典:Research Gate)
オープンAI
Googleが提供するDeepMindのライバルと目されているのがOpenAIだ。Open AI LPは、人工知能AIに関する研究機関であり、イーロン・マスクや、サム・アルトマンらによって2015年末にサンフランシスコで設立し、総額10億米ドルが拠出された。イーロンマスクは2018年2月に役員を辞任したが、引き続き寄付者として活動している。2019年には、OpenAI LPはマイクロソフトから10億米ドルの出資を受けた。2016年4月27日には強化学習研究のためのプラットフォーム「OpenAI Gym」のパブリックベータを公開し、2016年12月5日には、世界中のゲームやウェブサイトなどのアプリケーションに供給されているAIの一般的な知能を測定し、トレーニングするためのソフトウェアプラットフォーム「Universe」をリリースした。2018年2月21日には、マスクは自己運転車のテスラAI開発との「将来的な(利益相反の)可能性」を理由に取締役会の席を辞任した。2020年現在、OpenAIはサンフランシスコのミッション地区に本社を置き、旧パイオニア・トランク・ファクトリーの建物を、マスクが共同創業したもう一つの企業であるNeuralinkと共有している。OpenAIが非営利から営利へと移行した後、同社は従業員に株式を分配し、マイクロソフト社と提携し、前述の通り10億米ドルの投資パッケージを発表した。さらにOpenAIはその後、マイクロソフトを優先パートナーとして、その技術を商業的にライセンスする意向を発表しました。

(出典:Stock Market)
Big Leap in NLP
NLPとは自然言語処理(natural language processing)の略だ。人間が日常的に使っている自然言語をコンピュータに処理させるための一連の技術である。データベース内の情報を自然言語に変換したり、自然言語の文章をより形式的な表現に変換するといった処理が含まれる。一番小さいのがGPTモデル、2番目に小さいのがBERTの最大モデルに相当し、一桁以上大きいのがGPT-2モデルだ。まず、シーケンス・トゥ・シークエンス・エンコーダ・デコーダのアーキテクチャを採用していることがわかる。インターネット上に存在するTransformersに関する文献の多くは、まさにこのアーキテクチャを用いてTransformersを説明している。しかし、これはOpen AIのGPTモデルで使われているものではない。
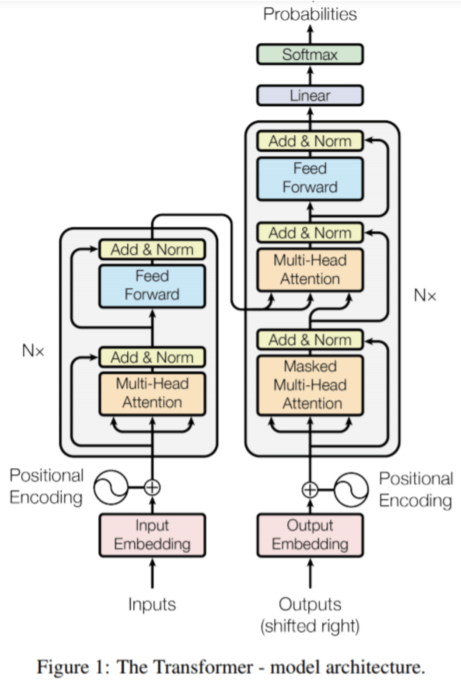
(出典:Towards Data Science)
DALL・E2
OpenAIは2022年4月6日に、文章から画像を生成するAI「DALL・E 2」を発表した。2021年1月に同社が発表した「DALL・E」の後継に当たるAIで、生成した画像を掲載するデモサイトも公開している。Twitter上ではAIが生成した画像を投稿している。下の写真(左)は、馬に乗る宇宙飛行士である。これらの画像は人工的なものだけど、利用用途を間違うとフェイクニュースに利用することも可能だ。いつの世でも、便利なツールには適切な利用方法とその高い倫理観が求められると思う。

(出典:ITMedia)
Vision Transformer
画像の変換器は画像分類タスクで非常に優れた性能を発揮する。分類クラスが18,000、高解像度の画像3億枚のを処理することのできる画像変換器がVision Transformerだ。この変換は自然言語処理(NLP)で選択されるモデルとなっている。自然言語(NLP)による成功に触発されて、可能な限り少ない修正で、標準的なTransformerを画像に直接適用することが実験されている。画像をパッチに分割し、そのパッチの線形埋め込みシーケンスをTrans-formerの入力として提供する。画像パッチは自然言語処理アプリケーションにおけるトークン(単語)と同じように扱われる。このモデルを教師あり方式で画像分類の学習を行う。Transformersには、ResNetsのような帰納的なバイアスがない。
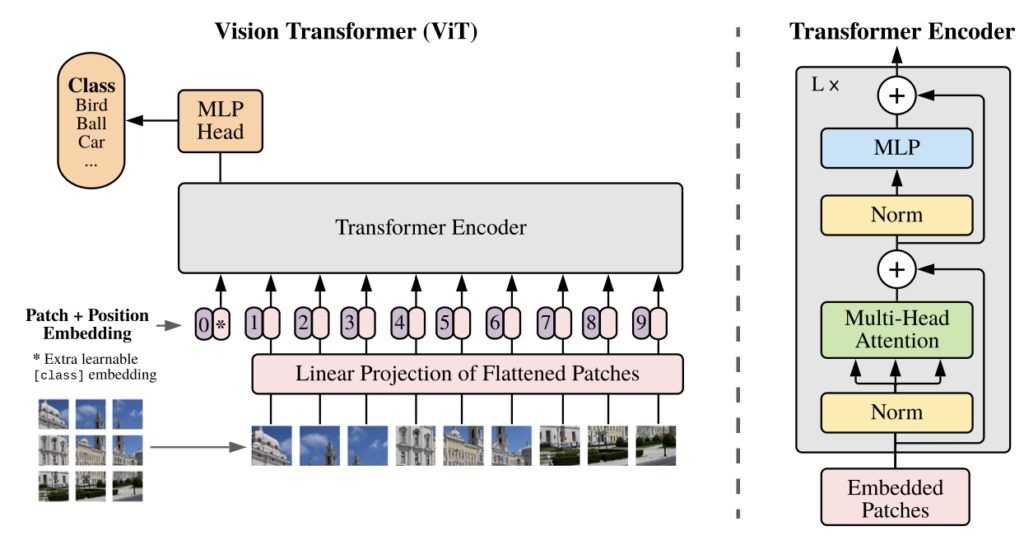
(出典:conference paper at ICLR 2021)
Network Architecture Search (NAS)
Googleは2018年に画像分類のCloud AutoMLをアルファ版として公開している。Cloud AutoMLは機械学習の専門家でなくても高品質な画像分類モデルを生成できる。Neural Architecture Search(略称:NAS)が従来のニューラルネットワーク設計と違うのは、NASはニューラルネットワークのアーキテクチャ自体を最適化するということだ。従来のニューラルネットワークでは、事前に人間がニューラルネットワークの構造を設計して、ネットワークの重みを最適化する。パラメータ最適化のみであればベイズ最適化や遺伝アルゴリズム、GridSearch等で実現されていたが、NASはそのさらに前段階で構造を最適化します。
1) 通常のニューラルネットワーク:ニューラルネットワークは重みを最適化し、目的関数を改善する。
2) パラメータ最適化を含んだニューラルネットワーク:通常のニューラルネットワークの前段階で最適なパラメータ(ニューロン数、ドロップアウト率、学習率等々)を探索する。
3) Neural Architecture Search:パラメータ最適化の前段階でニューラルネットワークの構造を最適化する。
(出典:Qiita)
まとめ
深層学習に関連した取り組みは、GoogleやOpen AIの取り組みに加えて、アマゾンの取り組みも注目すべきだと思う。AWSにおける機械学習(ML)の機能も充実している。今後、画像や動画の照合や分類などの誤り率はどんどん低下するだろう。ハードやソフトの発達により、時間が解決してくれる。我々が検討すべきはそれら技術の有効活用だ。深層学習は、自動車の自動運転を連想しがちだけで、社会の仕組みのありとあらゆることに適用が可能だ。しかし、現実の世界の処理と、機械学習での処理の両方に習熟した人は少ないので、両者の友好や融合、まっちんぐなどのよる知見の包括的な取り組みが必要だと思う。
以上
最後まで読んで頂きありがとうございました。
拝
(参考)
その1:ゲスト講師である原田達也教授の紹介と研究分野(前回の投稿)
その2:深層ニューラルネット(Deep Neural Network ⇨ 今回の投稿)
その3:ビッグデータの処理(Large Aboiunt of Data processing:次回の投稿)


