
はじめに
本日のGCL特別講座は、AIとゲームと題して、東京大学情報理工学系研究科の鶴岡慶雅教授に講義を頂いた。AIとゲームで連想するのはAlfa Goなどのプロ棋士よりも強いAIかもしれない。しかし、実は囲碁や将棋よりも、ポーカーや麻雀で上達する方が難しい。なぜかといえば不確かな情報をもとに不確かな感情の揺らぎを読み切りながら勝負をかけて行く必要があるためだ。なお、いつも書いているけど、これは講義メモではない。講義を拝聴して気になったキーワードを中心にネットや文献を調べて理解したことをまとめたものだ。なので、もし内容に問題があれば、その文責は自分にある。逆に、内容がわかりやすいとすればそれは鶴岡教授のおかげだ。また、範囲が広いので、次の2回に分けて投稿することにした。
AIとゲーム(その1):完全情報ゲーム (⇨ この投稿)
AIとゲーム(その2):深層強化学習、非完全情報ゲーム (次回の投稿)
鶴岡慶雅教授
鶴岡教授は、2002年に東京大学大学院工学系研究科博士課程を修了し、そのあとイギリスのマンチェスター大学や北陸先端科学技術大学院大学准教授を経て、2011年から現職。世界コンピュータ将棋選手権に4度優勝した「激指」を学生時代に開発されている。序盤は駒の損得、終盤は速度、駒の働きを考えて次の一手を決めるのがポイントという。

(出典:Slide Share)
完全情報ゲームと非完全情報ゲーム
囲碁や将棋のように全ての情報がデジタルに処理できる完全情報ゲームと、麻雀やポーカーのように不完全な情報を心理戦で勝負するような不完全情報ゲームがある。AlfaGoに代表されるAIゲームといえば前者が有名になったが、実は難しさでいえば、後者も難しい。なぜなら勝てるカードでもわざと勝負を避けたり、勝てないカードでもハッタリで勝負をしたりする勝負師もいる。また、1体1よりも大勢でやるトランプの王様ゲームのようなものや、ババ抜きなんかもコンピュータで処理しようとすると結構難しい。
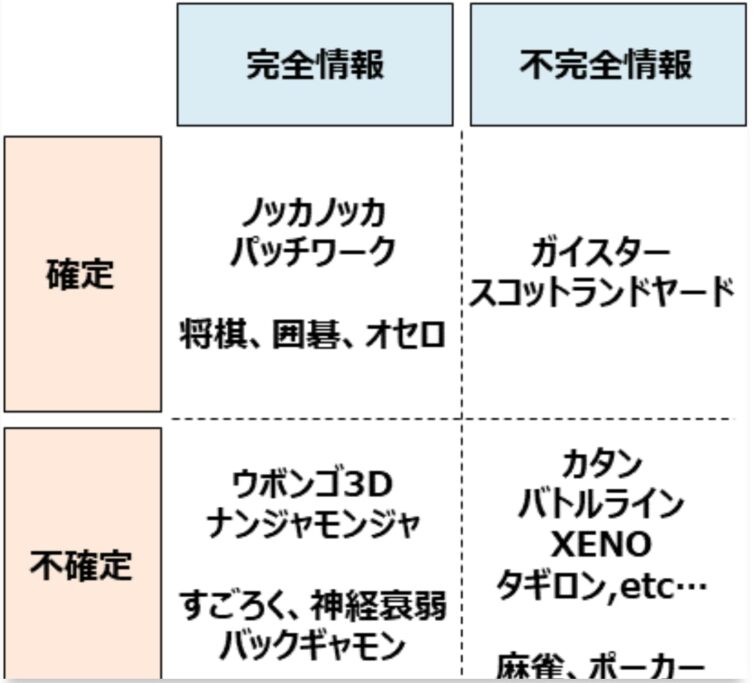
(出典:michipedia)
完全情報ゲーム
囲碁や将棋はコンピュータにとっては勝負しやすいフィールドかもしれない。例えていえば、サーキットでレーシングカート人間が100m走で競争するようなものだ。ババ抜きのようなトランプは非完全情報ゲームだ。これは例えていえば、田んぼの畦道(あぜみち)を車と人間が競争するようなものかもしれない。車は舗装された道なら早いけど、畦道は苦手だろう。
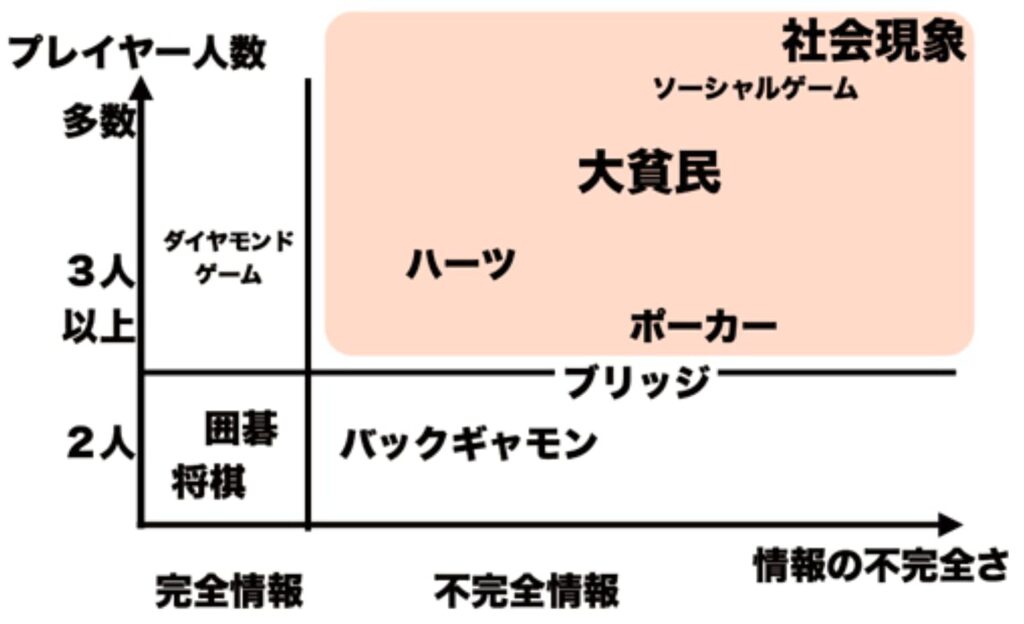
(出典:情報処理学会)
探索、汎化、学習
AIでゲームを処理するには、まずは必要な情報を検索して、そのデータを汎化し、学習する。汎化とはあまり聞きなれない用語だけど抽象化に近い意味のようだ。
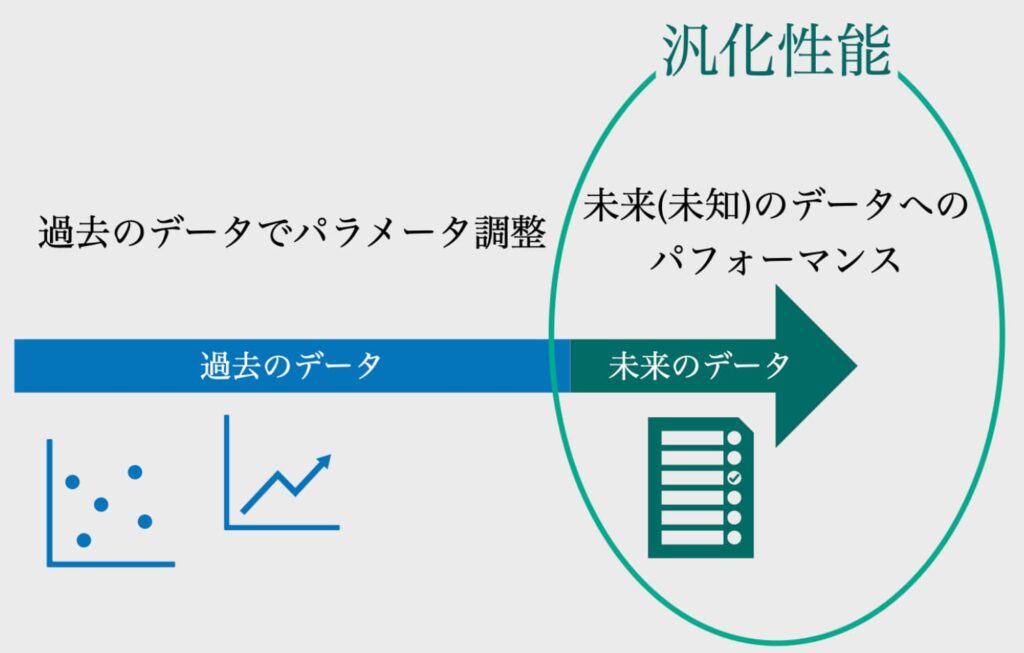
(出典:Contra)
モンテカルロ木探索(MCTS)
囲碁でいえば、まずは先手が黒の石を打ち、後手が白の石と交互に打つのがルールだ。モンテカルロ木探索(MCTS)は,木探索アルゴリズムの一種であり,平均的な結果が良い候補手を優先的に探索するアルゴリズムである。MCTSは汎用なアルゴリズムであり、囲碁などのゲームで有効性が確認されている。初めてプロ棋士に勝ったAlphaGoもこの検索を採用している。
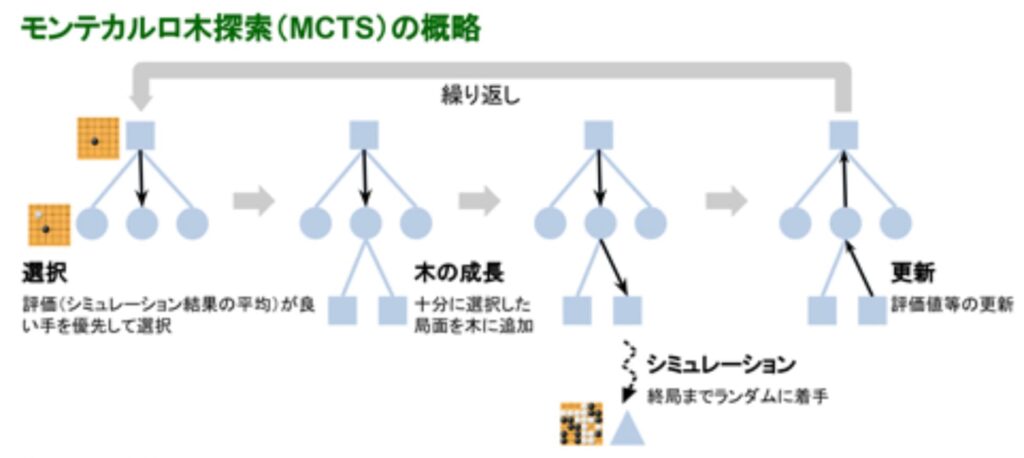
(出典:情報処理学会)
多腕バンディット問題
前述のモンテカルロ木検索(MCTS)は常に優れた性能を発揮できるわけではなく,比較的苦手なゲームがある。代表的なMCTSではシミュレーションを開始する節点を選ぶことを多腕バンディット問題(MAB)とみなす。MABのアルゴリズムと木探索のアルゴリズムは異なる点があり、MABの性質は成り立たない。多腕バンディット問題の解説としてスロットマシンの例があげられる。腕がK個あり、時間tを置いて腕i(t)を選択して、報酬Xi(t)を得るというものだ。この場合に儲けるためには、儲かるマシンに集中すること、儲かるマシンを見つけることが重要だ。
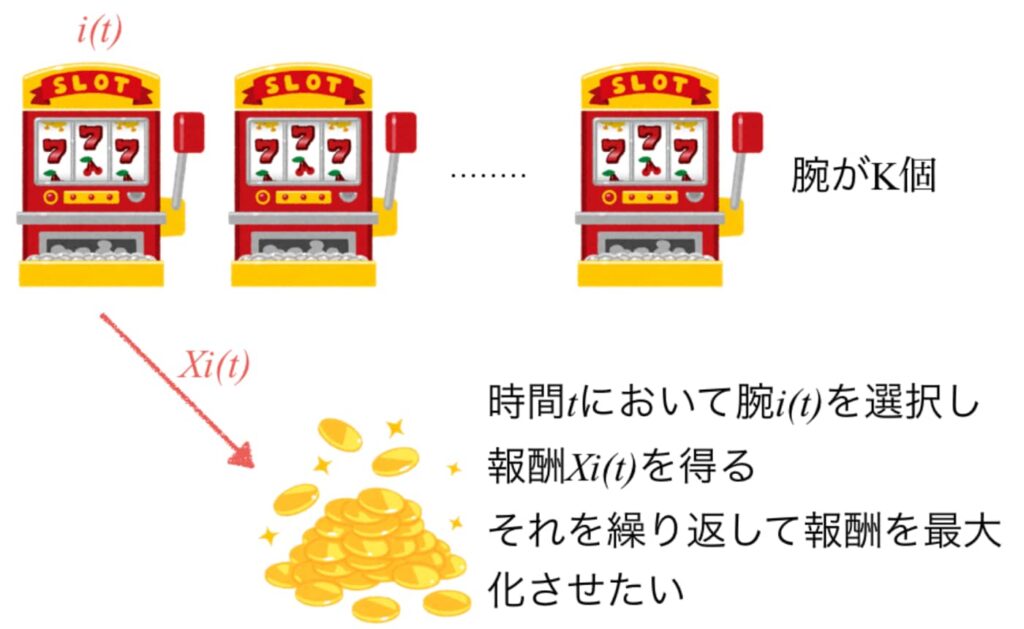
(出典:Speee Developer)
UCBとUCT
UCBsはUpper Conficence Boundsであり、多腕バンディット問題の近似解法だ。一方、UCT(Upper Confidence Tree)とは、探索と知識利用のバランスを取る1つの方法だ。UCB問題は2手目以降のプレイアウトに無駄が多く、相手の悪手に期待するような手を選ぶ。UCTはUCBを各ノードで適用し、勝率を各ノードに保存した木を成長させる。このようなミニマックス値に収束する。なお、Levente Kocsis と Csaba Szepesvári が2006年に発表した。Kocsis と Szepesvári は次の方程式のように想定している。
が最大となる子ノードを選択する。w は勝った回数。n はこのノードのシミュレーションの回数、N は全シミュレーション回数、c は定数。理論上は であるが、実際は探索が上手く行くように調整する。


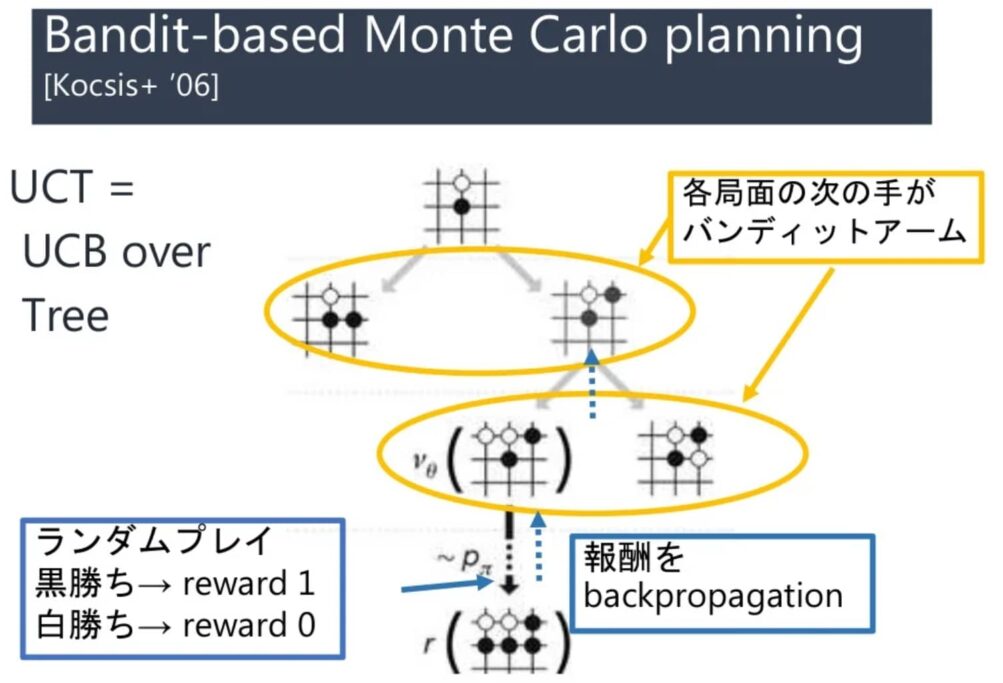
(出典:Slide Share)
ポリシーネットワークとバリューネットワーク
例えば、ニューラルネットワークを使うAlphaGoでは次の4ネットワークを学習している。
・ロールアウト用のポリシーネットワーク
・手の探索や強化学習の事前確率として使うポリシーネットワーク(SL)
・バリューネットワークの訓練用データを生成するポリシーネットワーク(RL)
・手の探索の精度を上げるためのバリューネットワーク(VL)
ポリシーネットワークとは、局面を入力にして、打ち手の確率を返すネットワークだ。一方、バリューネットワークは局面を入力にして、勝率を返すネットワークだ。ロールアウト用のポリシーネットワークは、単純な構成であるロジスティクス回帰を使っていて、プロの棋譜を教師として学習する。打ち手の選択精度は30%以下と低いが、他のネットワークに比べて動作が早い。従来の囲碁ソフトで使っていたような人的な細かい特徴量を入力にしている。ロールアウトとは、ある局面から乱数的に手を選んで終局まで進め、勝敗をシミュレーションすることを指している。手の探索や強化学習の事前確率として使うポリシーネットワークは、CNNを使っていて、同様にプロの棋譜を教師として学習する。打ち手の選択精度は55%程度と高いですが、ロールアウトに比べると2000倍程度動作が遅いです。なので、精度を要する部分にのみ限定して使います。なお、局面をほぼそのままCNNに入れるので、特徴的な要素はかなり減らしており、所謂DNNの特徴量学習能力を活用しています。
バリューネットワークの訓練用データを生成するポリシーネットワークは、上記ポリシーネットワーク(SL)で自分同士で対戦して棋譜を作り、勝ち負けの結果から強化学習を実施したものだ。
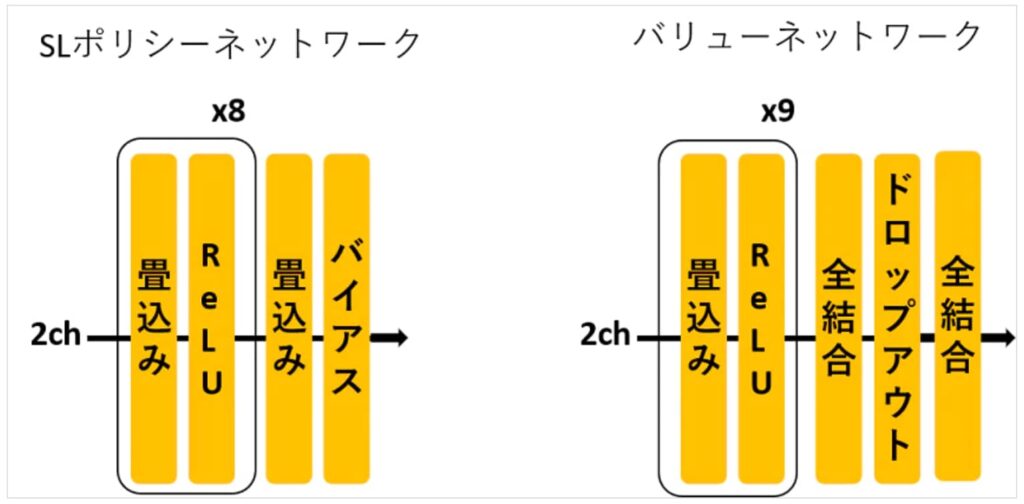
(出典:Qiita)
まとめ
完全情報ゲームは、囲碁や将棋などゲームを進めるにあたって必要な情報が基本的にデジタル情報として与えられ、かつ勝敗が明確なゲームだ。今回は、この完全情報ゲームを理解する上で重要なモンテカルロ木検探索や多腕バンディット問題、UCBとUCTなどの事項をおさらいした。次回は、深層強化学習と非完全情報ゲームについて深掘りすることとしたい。
以上
最後まで読んでいただきありがとうございました。
拝
1. 深層強化学習
・Deep Q-Network
・行動価値観数
2. 非完全情報ゲーム
・コンピュータポーカーの進歩
・ナッシュ均衡
3. 質疑
・心理戦を機械学習で上達することはあるか?
・弱い手でベットし、強い手でベットしない理由は?
・教師となる報酬が得られればQ学習が可能か?


