
はじめに
ユーザのためのAI入門の第二回の講義を4月13日に受講した。その1ではゲスト講師である原田教授や研究分野などを紹介した。その2では、講義頂いたうち深層学習関連についてまとめた。今回は、その3としてビッグデータの処理関連についてまとめたい。
その1:ゲスト講師である原田達也教授の紹介と研究分野(前々回の投稿)
その2:深層ニューラルネット(Deep Neural Network :前回の投稿)
その3:ビッグデータの処理(Large Aboiunt of Data processing ⇨ 今回の投稿)
Large Amount of High-Quality Training Data
画像を認識するには、元となる画像データが必要だ。ここでは代表的に3つの画像データを紹介頂いた。注目すべきは画像データの量だ。初期の発展を支えたImageNet Realは120万枚の画像データだが、JFT-300Mでは3億枚、GraspNetでは10億枚だ。これだけ増えると教示なしでしか対応できない。しかし、人間の躾や教育と同じで初期にしっかりとした教育をしておくことが重要であるという点も理解しておく必要があると思う。
ImageNet Real
深層学習による画像認識の革新を支えたのはImageNetプロジェクトであり、1400万枚以上の画像に手書きのアノテーション(注釈)が施されている。アノテーションとは、特定のデータに対してメタデータとしての情報タグを付加するという意味だ。さらに、100万枚の画像には境界もしくは囲みボックスとしてのバウンディングボックスも提供されている。ImageNetには2万以上のカテゴリーがあり、典型的なカテゴリーには数百枚からの画像が用意されている。ImageNetプロジェクトでは2010年からILSVRCコンテストを開催し、原田教授率いるチームが2012年のILSVRCコンテストで大活躍したことはその1で投稿した通りだ。
(出典:@IT)
The JFT-300M
Googleが開発した巨大なデータセットは、3億枚の画像を集約しているJFT-300Mだ。そのカテゴリーも広範だ。18,291のカテゴリーがあり、動物なら1,165種類、乗り物なら5,720種類のデータセットがラベル付けされている。ラベル付けは流石に手動では無理で、自動で付与されていて、1画像に1つまたは複数のラベルがつく。合計3.75億個のラベルなので、平均すると1画像に1.26ラベルとなる。これはすごい。
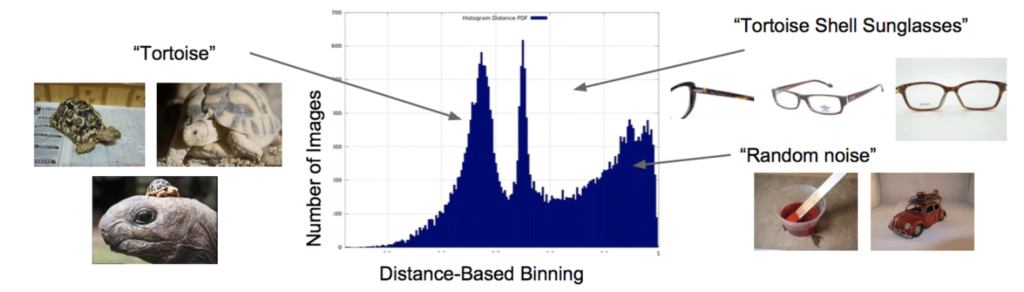
(出典:Qiita)
GraspNet-1Billion
ロボットを操作する上で、ロボットが様々な状態でバランスを保持するように制御することは重要である。下の写真は、10億枚の保持ポーズと、97,280枚のRGB-D画像を元に乱雑なシーンから複数の把持(Grasp)候補を検出することに成功したという。一発で検出する。2次元の画像中のベクトルを定式化し、ベクトルの原点と方向を同時に推定する完全畳み込みネットワークを検出することで、ロボットを制御する仕組みだと理解した。

(出典:Complex & Intelligent Systems)
Self Supervised Learning (SSL)
データ量を増やせば画像認識の精度は高まるが、それではデータ処理の時間や前処理の時間が増大する。より少ないデータでより精度の高い画像認識を実現できないかとグーグルがトライしたのがSSL(Self Supervised Learning)だ。直訳すると、自己監視型学習か。ここで使われる技術が対照学習(Contrastive Learning)だ。つまり、ある画像とそれを斜めにした画像、開店した画像、一部をマスクした画像、輪郭にした画像などと比べることで理解度を深める手法だ。下のグラフに示すように、CimCLRではデータ量を増やすことで精度を約70%から約76%まで向上させているが、Supervised(=SSL)ではデータ量を増やさずに精度を高めることに成功している。なお、SimCLRの研究では、複数の組み合わせにより精度を高め、3つの知見が指摘されている(出典)。
知見1:対応するビューを生成するために使用される画像変換の組み合わせが重要。
知見2:非線形な投影が重要。
知見3:スケールアップすると、パフォーマンスが大幅に向上する。
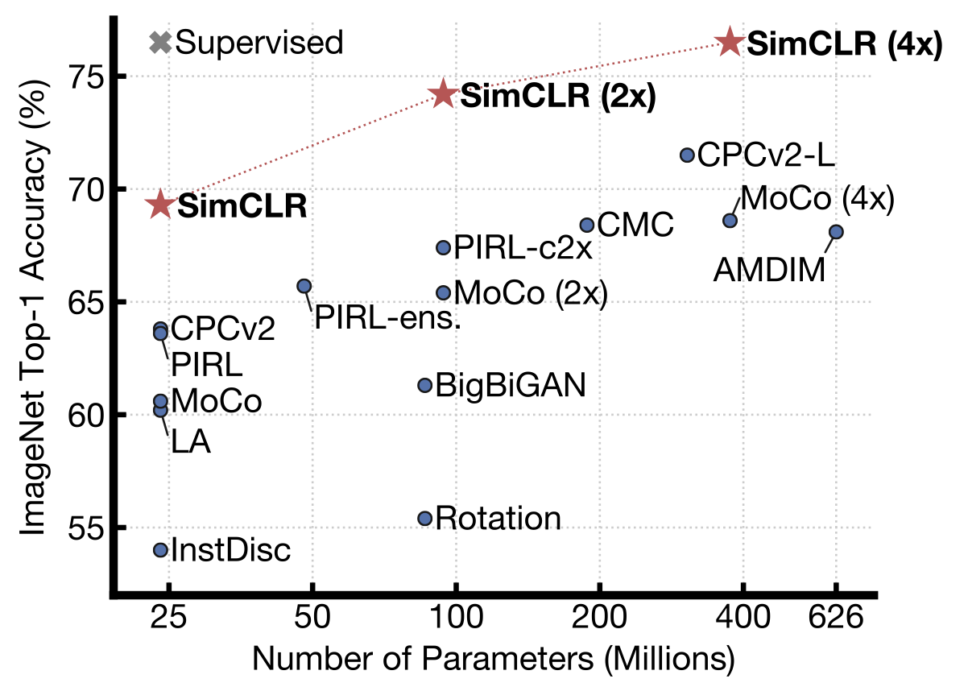
(出典:paper)
SSLは伝達学習に代わる事前学習法である。SSLは膨大なNLPデータセットから生まれたが、コンピュータビジョンにおいても大きな進展を見せている。コンピュータビジョンにおけるSSLは、回転やビデオの順序付けのような前段階のタスクから始まった。これらの方法はすべて、人間の注釈者なしでラベルを生成する。SSLは一つの画像から複数の画像を抽出、変換し、それによって学習するという優れた仕組みと言える。
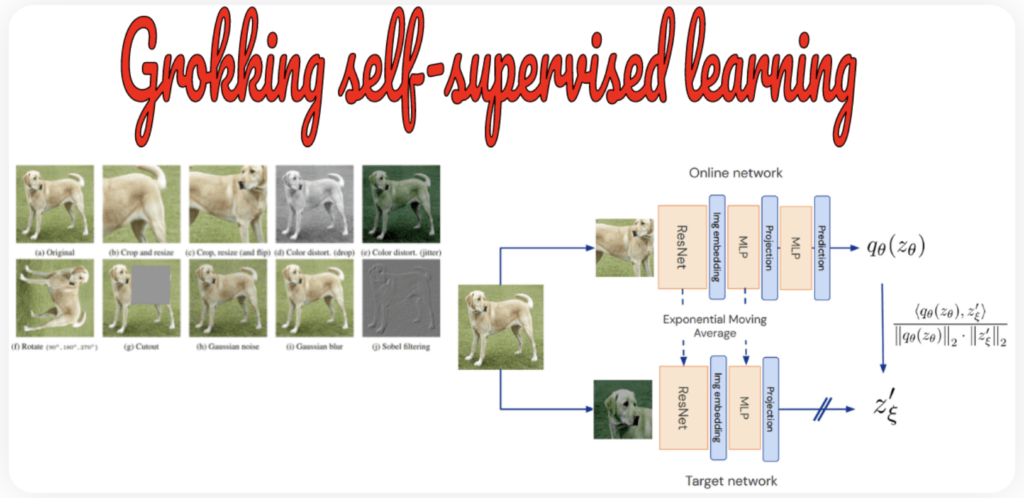
(出典:AI Summer)
Self-supervised training
群盲象を評すという。これは、数人の盲人が象の一部だけを触って感想を語り合うという寓話だ。SSLやSST(Self-supevised training)はこの逆のような気がする。つまり、象の写真のパーツにフォーカスして、一枚の像の写真から耳の写真、足の写真、尻尾の写真と数多くの写真を生成し、それを回転したり、反転させたり、色を変えたりして多くのデータセットを生成する。そして、それらを用いて像とは何かを理解する。人間も実はこのような処理をしているので、例えば頭隠して尻隠さずの尻だけを見て、誰かを理解する。人工知能もこのようなプロセスを踏まなければ確かに画像認識の精度は高まらないだろうと思った。
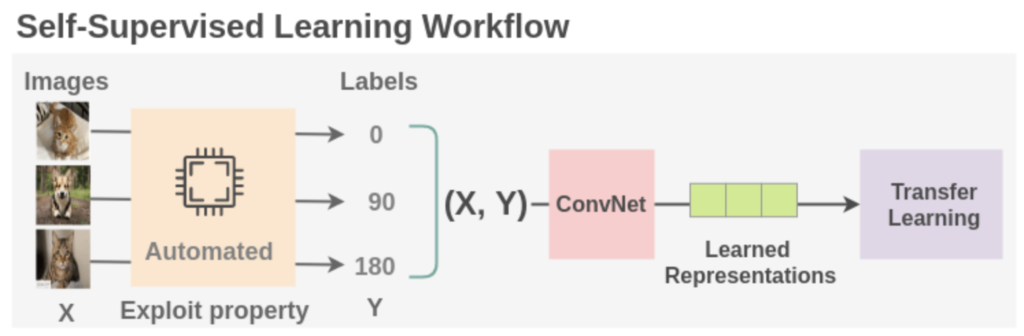
(出典:Amit Chaudhary)
Sim2Real
下の動画は、自動運転においてカメラから取得した動画からリアルタイムに各種オブジェクトを認識する模様を示したものだ。人間の認識率を機械はすでに超えていて、人間が運転するよりも機械に運転してもらう方が安全な世界に突入しているような気がする。ただ、人間であればすぐにわかるような基本的な認識が欠落している可能性があるので、地道な改善は当然必要だ。また、実際に道路を走行しなくて、シミュレーションでの走行実験を繰り返すことも可能だ。例えば、歩道から突然幼児がボールを追いかけて道路に飛び出した時に安全に停止したり、避けることができるかという実験をリアルにすることはできないが、シミュレーションであれば可能だ。プロの棋士にアルファーGOが勝利したように、運転は機械に任せる時代に向かっている。しかし、プロ棋士の存在が否定されるわけではない。プロ棋士は、アルファGOを活用してさらに高いレベルを目指すことが可能だ。その意味では、目的地を設定すれば自動運転車はそこまで運んでくれるかもしれないが、そもそもどこに行くのか、目標地をどこにするべきか、どこに行きたいか、なぜかといった意思決定は人間しかできない。個人的には、ゴルフ場への往復は自動運転に任せたいけど、ゴルフ場に行く前にコンビニに寄りたいとか、打ちっぱなしに行きたいとか、そのような意志は人間が行うべきだ。
(出典:YouTube)
まとめ
深層学習時代のAIというタイトルのもとでの原田教授の講義を拝聴した。その一つ一つが非常に興味深い。全てをもっと深く理解したくなる。講義の中で、ビッグデータからグッドデータという話があった。膨大なデータを駆使して業務改善を図るべき業界もあれば、少ないデータだけど非常に有益なデータがあればそれを活用する手法もある。1つの画像データから複数の画像データを抽出して自己学習する手法(SSL)などは非常に興味深く感じた。次回の講義は東京大学情報理工学系研究科の山肩洋子准教授による「AI実践の基礎」だ。できれば、事前に山肩准教授の経歴や研究レポートなどを拝読しておいて、質問の準備をしておきたい。
以上
最後まで読んで頂きありがとうございました。
拝
(参考)
その1:ゲスト講師である原田達也教授の紹介と研究分野(前々回の投稿)
その2:深層ニューラルネット(Deep Neural Network :前回の投稿)
その3:ビッグデータの処理(Large Aboiunt of Data processing ⇨ 今回の投稿)


