
はじめに
今回は、GCL特別講座の第9回として、LINE株式会社の井尻善久さんから大規模AIモデルの現在と将来というテーマでお話を拝聴した。正直、LINEのCLOVAの話が中心かと想定していたけど、期待を遥かに超える素晴らしい講座だった。何が素晴らしいかといえば、井尻さんの引き出しの多さと卓越したその豊富な見識だ。今回の講義は非常に幅広く、奥も深く、感銘を受けたことも多いので、三回にわたって投稿することにしたい。なお、これはいつも書いていることだけど、これは講義メモではない。講義を受けて、印象に残ったことを自分なりにネットや文献で調査して、理解したことをまとめたものだ。なので、もし内容に問題があれば文責は自分にあり、逆に内容が良ければそれは講師である井尻さんのおかげだ。
その1:LINEにおけるAI研究とビジネス化 (⇨ 今回の投稿)
その2: LINEの大規模AIモデルに向けて (次回の投稿)
その3:これからのAIと見えてくる可能性 (次々回の投稿)
講師は井尻善久AI開発室室長兼コンピュータビジョンラボ長
講義に先立ってはオムロン出身とだけ紹介があった。井尻善久さんからも自己紹介があったけど、どうもスッキリしない。自分も京都生まれなので、すぐに分かったけど、京都出身のアクセントだった。京都で生まれて、京都で育って、オムロンに入社されたのだろうか。どのような経歴でこれだけの見識を得られたのだろうか。その点を中心に、経歴を調べてみて納得がいった。どう言うことかといえば、オムロンに入社されたのは、京都工芸繊維大学大学院工芸科学機械システム専攻修士課程を修了された2002年だ。ストレートであれば、1978年ごろの生まれで、44歳前後だろうか。そして、オムロン株式会社に入社後は顔の検出・認識や監視カメラ応用などの従事する一方で、名古屋大学大学院情報科学研究科メディア科学専攻博士課程を2012年に終了されている。その当時と想定されるけど、マスクやメガネなどを装着した人物の認識技術に関して、「多様な属性に柔軟に対応できる 人物属性認識の準教師付き学習フレームワーク」という論文をオムロンと名古屋大学の連名で電子情報通信学会で発表されている。2009年画像センシングシンポジウム高木賞、2009・2011年電子情報通信学会PRMU研究会研究奨励賞受賞し、翌年の2010年からはオムロンで物体検出・セグメンテーションなどの商品化を進める一方で、奈良先端科学技術大学院大学の客員准教授を務め、人・顔画像処理・産業用画像処理、ロボティクスに関する研究開発に従事されている。講義でも、2002年から2010年は先輩の切り拓いた世界を支え学んだ下積み時代(守)、2010年から2018年は自分で切り拓いたチャレンジ時代(破)、そして、2018年以降は新たなやり方を試している時代&次の下積み時代(離)と俯瞰されている。実際、LINEに転職されたのが2021年であり、AI開発室の組織化やComputer Vision Labを立ち上げるなど精力的に活動されている。研究者としての技術革新への熱い想いとビジネスマンとして研究成果を事業化して社会の役に立ちたいという気持ちが穏やかな話し方から溢れ出ている感じだった。
(出典:LINE)
LINEの現状
LINEの収益状況
実はSEとして2018年ごろにLINE WORKSとコラボして日系金融系のお客様に提案する機会があった。当時の日系金融企業に各種クラウド系サービスを提案しても既存のオンプレミスのシステムよりもセキュリティレベルがどうしても低下する部分があるので難しいという判断を示す一方で、LINE WORKSには前向きだった。当時提案していた某銀行のシステム担当者の方に伺うと、現状行員は主にプライベートでLINEを活用している。これを禁止するわけには行かないけど、業務用としてはLINE WORKSを利用してもらえばセキュリティレベルが上がるので上層部を説得できるということだった。銀行内での意思決定のロジックに妙に納得したのを覚えている。そんな当時は、LINEの売上は下の図(左)に示すように毎年増収で絶好調と言いたいところだったけど、営業収益で見ると赤字計上が先行していて厳しい状況だった。これを打破したのはZホールディングへの移行で、2021年には145億円の営業収益を叩き出している。この黒字化の意義は大きい。これからのLINEの快進撃が始まる狼煙のように感じるし、そのタイミングで井尻さんがヘッドハンティングされたのも意味のあることだと思う。
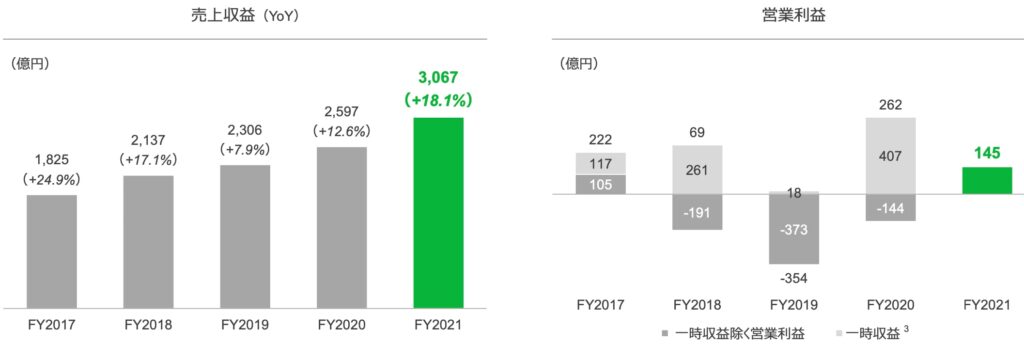
(出典:Zホールディング2021年度決算報告書)
LINEのMAU
講義の中では、2022年3月時点でのMAU(Monthly Active Users)について紹介があった。MAUとは、各種サービスで月に1回以上利用するユーザーの数で、日本が9,200万人、タイで5,300万人、台湾で2,200万人、インドネシアで900万人、これら4つの国・地域で1億7,600万人だ。約1年前の2021年6月の時点では、主要4ヶ国のMAUが約1億7,100万人だったので500万人に増加となる。下の図は2021年9月時点のMAUだけど、全世界では1億8,900万人となる。日本やアジアだけではなく、世界で戦える企業になってほしいと思う。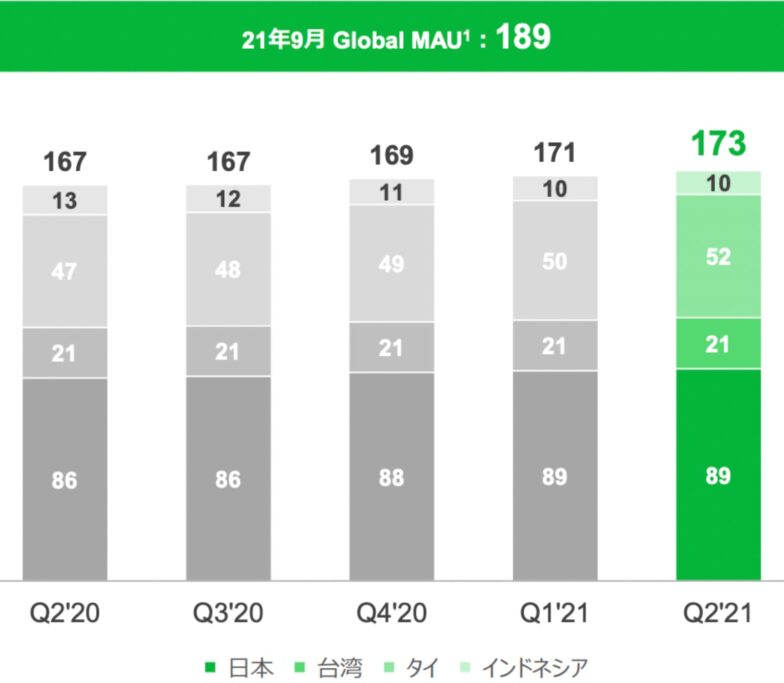
(出典:Insta Lab)
LINEの年代別男女別国内ユーザー数
これは講義では言及されなかったけど、LINEの国内ユーザの内訳が気になった。調べてみると、最も多いのは20代だけど、次に多いのが意外と50代以上だった。40代や30代も多い。2015年から3年間ほどは名古屋に赴任して、関東・中部・北陸を中心に全国の小中高校を訪問して、ケータイのモラル教室の講師をしたときを思い出す。当時はLINEの利用者が高校・中学・小学生と若年化する波と、生まれた時からLINEを使うスマホネイティブの波に挟まれていたのが、小学生の2-3年生の子供たちだった。子供たちにとってはLINEは生きていく上で欠かせない空気のような存在にすでになっていたけど、最近はどうなのだろう。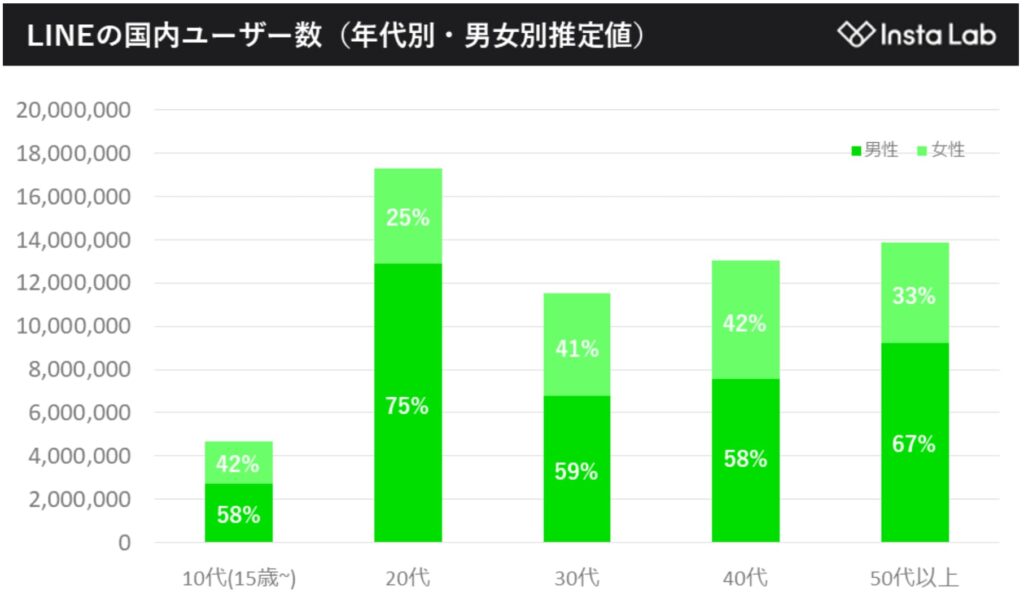
(出典:Insta Lab)
スマートポータル=スーパーアプリ構想
LINEの構想はLINEを入り口とするポータル戦略であり、そこからさまざまなサービスにシームレスにつながるというスーパーアプリ構想を目指している。これはある種当然というか、必然的な戦略だろう。実際LINEを入口に金融系やエンタメ系、ショッピング系につながるのは便利だ。

(出典:Logmi)
LINEの技術組織
LINE株式会社は不思議な会社だ。元々は韓国のIT企業であるNAVAR系の日本子会社(NHN Japan)だった。2011年3月11日の東日本大震災を目の当たりにして、何か貢献できないかと考え、当時、欧米や中国、韓国で始まったSNSの日本版を作ろうとトライして、なんと2011年6月にはサービスを開始している。LINEでは既読を確認できるのが特徴の一つだけど、これは返事がなくても、読んでくれたかどうかを確認したいという安否確認の意味を持っている。LINEにスタンプ機能を持たせて大ヒットしたが、その舞台裏には元Live Doorの技術者たちの活躍があることはあまり知られていない。また、アジア・グローバルの戦略を担うのは親会社のNAVARである。この辺りは以前投稿した「LINEの功罪と将来のあるべき姿」を参照いただきたい。ここで書きたかったのは、LINE株式会社の技術職の構成だ。国内に800人、グローバルに2,900人とある。やはり残念ながら研究開発は韓国NAVARとの連携が前提となっているようだ。日本人が頑張って研究開発した成果が世界で活用されることは素晴らしいことだけど、日本社会の公益にも還元される仕組みになっていて欲しいと思う。

(出典:Logmi)
LINE AIの4つのR&D Vision
300以上のアイデアから5人のエディターが4つに絞り込む。この4つのアンブレラトピックは、未来予測を抽象化した技術コンセプト化だ。これらの技術コンセプトは、LINEやNAVARが直接事業化するかどうかではなく、今後3年から5年のスパンで市場に展開されるサービスとアンブレラトピックの関係をまとめている。下の図の横軸は2020年から2027年のタイムスパンでの時間軸だ。そして、縦軸はDisruptive(破壊性)だ。つまり、下は社会の養成に応えるための研究開発であり、上になると社会をより革新するための研究開発となる。
・Digital Me:自身のIDのデジタル化にみならず、個人の個性や好みまで含めたデジタル化だ。
下の図の最も左下なので、直近に実現し社会に貢献する技術。
・Generative Intelligence:コンテンツの連携。下の図で左上なので、直近に実現し、社会を革新する技術。
・Trustworthy AI:信頼できるAI。下の図で右下なので、実現には時間がかかるが社会に貢献する技術。
・Dark Data:利用されていないデータ。下の図で右上なので、実現には時間がかかるが革新的な技術。
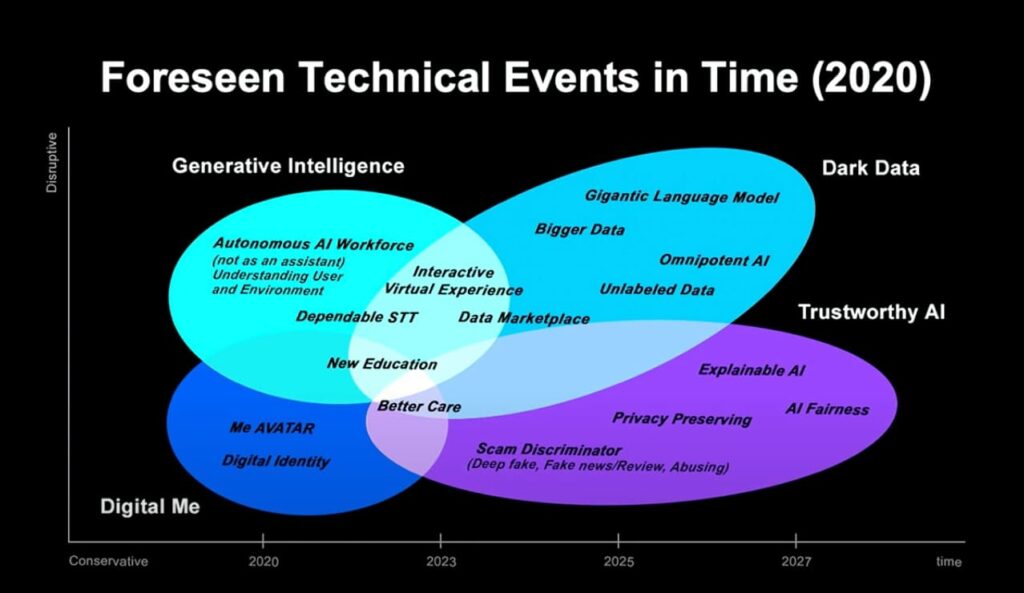
(出典:YouTube)
Digital Me
現在の自身のIDはなんだろう。免許証か。パスポートか。指紋認証や顔認証もしている。個人をいかに正確に認証するかは本質的に難しい課題だけど、自身のIDをデジタル空間に作り、バーチャルな世界でもリアルな世界でもシームレスに使えれば、利便性は高まるだろう。LINEが考えるDigital Meは個人のデジタルIDに留まらず、個人の個性や好みまで含めたデジタル化だ。ただ、利便性とセキュリティのトレードオフをどう考えるのかが悩ましいのかもしれない。便利にすればするほど悪用された場合のハレーションが大きくなる。でも、いつまでも変革しなければ、世界は広がらない。さまざまな配慮や制限をかけつつパフォーマンスを高めたいと言うのが井尻さんをはじめとする関係者の思いだろう。

(出典:Logmi)
Generative Intelligence
Generative IntelligenceはAIの応用の進化の方向を示している。画像とテキストの既存コンテンツから新しいコンテンツを自動生成・創作を可能とするAIだ。さらには、深層学習の発展によるAIの認識結果の総合作用、つまり異なるコンテンツの関連付けといった広がりがある。これまではコールセンターでのAI対応や、LINE上の「りんな」などでテキストでのAI対応などは実現しているが、今後はこれらが相互に関連つけながらさらに新たなコンテンツを生成・創作するものだ。テキストを朗読するときに、同じコンテンツであっても、明るい雰囲気のナレーションで聞くのと、暗い雰囲気のナレーションを聞くのでは印象が全く異なる。コンテンツの内容に応じてナレーションの雰囲気を自動で調整することができれば、コールセンターでの会話も、さらに自然なものになるだろう。システムは感情を持たないけど、コンテンツに沿った雰囲気でナレーションを流すと人は親しみやすさなどを感じたりすると思った。
(出典:Logmi)
Trustworthy AI
これは信頼できるAIだ。今後のAIの進化に伴ってプライバシーとデータのガバナンスの説明責任を果たすことがますます重要となる。納得性の向上や公平性の確保などの課題を解決することが求められる。さらに、データ自体についてフェイク情報の流通やデータの改竄がないなど、データの信頼性や信憑性を高める必要がある。ここで悩ましいのは、個人のプライバシーを守ることと、積極的に活用することと、公共の安全を担保することは、トレードオフの関係にある。従来のAI開発は”Expert-level Quality”の達成が主眼だったけど、井尻さんが考えるAIはひとに寄り添うAIで、頑健性(Robust)、倫理性(Fair/Privacy-preserving)、説明性・透明性(Explainable/Tranparent)、そして改善性/制御性(Improvable/controllable)だ。相互に対立する概念を高い次元で満足させることが社会にITサービスを提供する企業の責務であり、まずはAIが有するリスクの理解が必要と注意喚起されていた。
(出典:Logmi)
Dark Data
ダークデータは、ダークウェブで扱われるデータという意味ではなかった。そうではなく、これまで使われなかった眠っているデータパワーの活用というイメージだ。利用されていないデータは全体の約9割とも言われており、活用されずに眠っていたビッグデータを活用する方向はよく理解できる。ただ、この技術の難しい点は、必ずしも精度の高いデータや正しいデータばかりではないということだろう。現在の深層学習では、教師ありデータやラベル付けされたデータなどが中心だけど、今後は間違いを含むデータを精査し、取捨選別しながら有効に活用するという技術が重要となってくるのだろうと思った。

(出典:Logmi)
まとめ
今回の講義はLINEが考えるCLOVAの戦略といった話かと思ったら、期待を遥かに超える素晴らしい内容だった。LINEの戦略やAIモデル研究の最新の動向などを惜しげもなく講演頂いた。ただ、ネットで色々とキーワードから調べるとLINEのさまざまな関係者やキーパーソンの過去の発表なども見つかり、参考にさせて頂いた。また、個人的には井尻さんの経歴が気になった。私は、京都市に生まれ、七条中学を卒業後、奈良県の大和郡山市にある奈良高専に進学して、卒業後はKDD(現在のKDDI)に就職して、名古屋に単身赴任しながら40年以上経ってしまった。井尻さんの経歴を拝見すると、京都、名古屋、奈良、東京と重なる部分が多い。いつまで経っても抜けない京都弁も共通しているように感じるし、内に秘めたる闘志というか、熱い思いと人当たりの良さなどにも親近感を感じました。今回は貴重な講義本当にありがとうございました。
以上
最後まで読んでいただきありがとうございました。
拝
参考:コンテンツの続き(想定)
その2:LINEの大規模AIモデルに向けて
AIカンパニーが提供する3つのサービス
_LINE AI Call
_LINE eKYC
_CLOVA OCR
大規模AIモデルの3つの技術革新
_1つ目の技術革新:TRANSFORMER(2017)構造の単純化
_2つ目の技術革新:GPT(2018) 教師なしの機械学習
_3つ目の技術革新:Prompting(2018)
さまざまな取り組み
_国立国会図書館の文献デジタルアーカイブ化
_大量の会話文もデジタル化 =CLOVA Note
_言語モデル自身がテキストの有害性を評価
Differential Privacy(DP)
Privacy Preserving Data Synthesis
Voice Synthesis + Avatar
その3:これからのAIとそれにより見えてくる可能性
大規模言語モデルにおける汎用事前学習の開発競争
対話システムのライブコンペティション
_解説から俳句を生成するプロンプティング
_商品解説文からキャッチコピーを生成するプロンプティング
_メモ文から営業日報を自動生成するプロンプティング
_考え方を教えることで推論精度を高めるプロンプティング
目的志向特化型AIの先に見える汎用AI
_MiLAI:Mixed LINE AI
_マルチモーダル(2021年2月)
_Flamingo(2022年4月)
_Imagen(2022年5月)
_Gata(2022年5月)
_Parti(Pathways AutoRegressive Text-to-Image model:2022年6月)
スケーリング効果
強いAIと弱いAI
AIに感情がある可能性
汎用人工知能
AGI survey 2020
未解決な問題


