
はじめに
今日のGCL講義は「AIと人文学」とちょっと面白い組み合わせだった。ゲスト講師は国立情報学研究所(NII)の北本センター長だ。一言で言えば、理系と文系がお互いの違いを認めた上で協力し合う呉越同舟のようなプロジェクトだと思った。なお、いつも記載するが、これは講義メモではない。講義を拝聴して興味深いと思ったことをネットや文献で確認して理解したことをまとめたものだ。なので、もし内容に問題があれば文責は自分にある。逆に内容が良かったとすれば、それは講義いただいた北本講師のおかげだ。

(出典:四文字熟語)
ゲスト講師は北本朝展教授
1969年に川崎で生まれ、1997年3月に東京大学の博士課程を修了された(工学博士)。その後、学術情報センターに移り、2000年に国立情報学研究所(NII)の助手、助教授を経て、2008年に准教授に就任される。2003年には、14万件超の気象衛星画像データベースを核として、過去のあらゆる台風の情報を網羅した「デジタル台風」を開設されて評判になる。さまざまなデータの結びつきから新しい情報を汲み出すための方法論を開拓されている。現在は、ROIS-DS人文学オープンデータ共同利用センターのセンター長をされている。専門は情報学、デジタル・ヒューマニティーズ、データ駆動型サイエンスなどだ。

(出典:NII)
デジタル人文学とは
人文学は、精神的価値、歴史時間及び言語表現に関する世界の知的領有と知識についてのメタ知識と言える。デジタル人文学は、デジタルの技術を活用して人文科学を行う学問だ。さまざまな領域の研究テーマや素材、資源に対して、AIを応⽤したり、ビッグデータを効率よく扱うことで、領域を複合させたり、思ってもみなかった新たな研究領域を生む。個人や社会が抱える課題の究明を、情報技術を応用すること解決する。

(出典:立命館大学)
眼の誕生
下の図の図書は、イギリスのバイオミメティクス分野の動物学者であるアンドリュー・バーカー博士の著書だ。生物がカンブリア紀に眼の機能を獲得して、生物間の軍拡競争につながったと提唱した。この光スイッチ説には賛否があるようだけど面白い考えだと思う。眼の次は口。人類は言葉を操ることで生物界の頂点に君臨した。口の次はどこだろう。北本講師は、AIという新しいツールによって見えるものが変わるという。近読と遠読。遠読(Distant reading)とは大量のテキストを機械が読み込み、データからパターンを見出す手法だ。大規模なデジタルライブラリから得られる文学データに計算手法を適用する文学研究のアプローチである。文学データを分析するさまざまな計算アプローチには、マクロ分析、文化分析、計算形式主義、計算文学研究、定量文学研究、アルゴリズム文学批評などもある。

(出典:アマゾン)
N-gram
N-gramモデルとは、N-1個の単語の並びが与えられたとき、その並びの後に続く可能性が高い単語を予測するモデルである。これはテキストのコーパスを用いて学習させた確率的モデルである。このようなモデルは、音声認識、機械翻訳、テキスト入力予測など、多くの自然言語処理アプリケーションで有用である。N-gramモデルは、ある単語列がコーパスのテキストに出現する頻度を数え、その確率を推定することで構築される。単純なN-gramモデルでは限界があるため、平滑化、補間、バックオフなどの手法で改良されることが多い。N-gramモデルは言語モデル(Language Model:LM)の一種で、単語列の確率分布を求めるものである。
(出典:Devopedia)
くずし字認識
日本には数億点の古典籍や古い文書が存在するが、一方でくずし字をきちんと読めるのは数千人と全人口の0.01%未満だ。このため、国文学研究資料館はくずし字データセットを構築して、CODHがオープンデータとして公開している。2020年7月時点で文字種4,328、文字数1,086,326だ。データセットとして公開することでAIによるくずし字認識研究が活性化し、古典文化を現代人が活用することが可能となった。これは素晴らしい取り組みだと思う。

(出典:井上会)
kaggle
Kaggle(カグル)とは、企業とデータサイエンティストをつなぐ為のプラットフォームだ。40万人以上のデータサイエンティストが集まり、データ解析のスキルを試している。下の図に示すように、企業が提示した課題に対して、データサイエンティストたちが高い精度のモデルの提案を競う。精度の高いモデルを作成することに成功すると賞金を得ることが出来るという仕組みだ。Amazon, Facebook, Walmartなどの企業がコンペを実施していて、日本でもその認知度は高まっている。これは面白い。
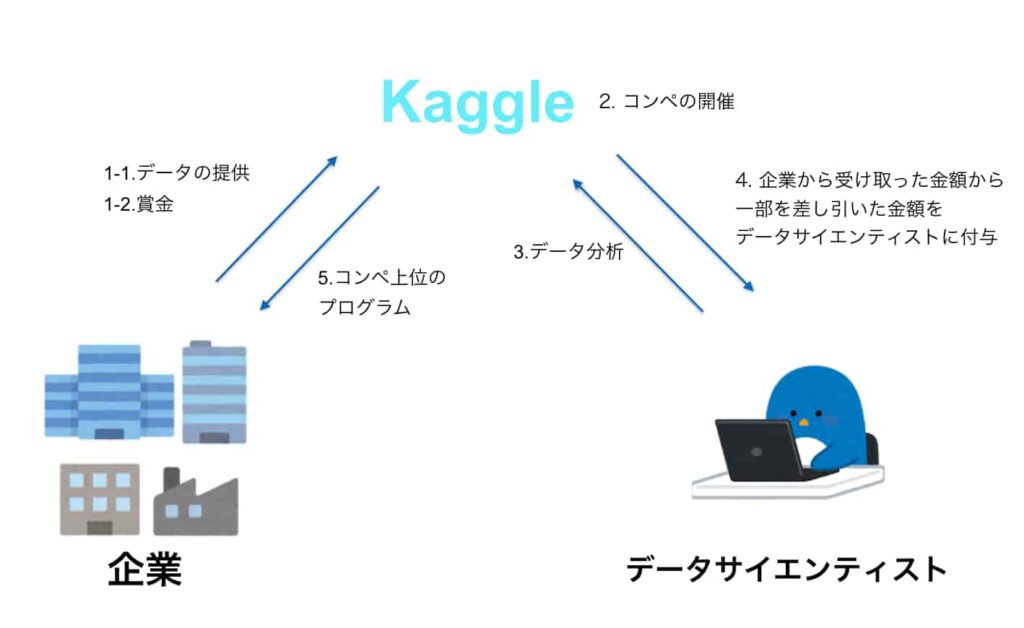
(出典:AI Academy Media)
くずし字データセット
古い文献のくずし字を解読するには、データセットと言う辞書が必要だ。例えば、日本古典籍くずし字データセットは、人文学オープンデータ共同利用センター(CODH)が提供しており、前述の通り4,328文字に対して1,086,326文字を提供している。一文字あたり、平均251文字が登録されている。これは便利だ。下の図は、「院」で検索した場合の文字の一部であり、パターンマッチングの技術を用いて照合している。

(出典:CODH)
物体検出
くずし字は文字だったけど、原理的には物体の照合にも応用できる。画像中に存在する物体を認識する技術は自動運転の分野では必須だ。インスタグラムなどでも似たような画像を検索する機能がついていて便利だし、ついつい連続して検索してしまう。

(出典:NII)
みを:AIくずし字認識アプリ
「みを」については、前回の講義でも説明してもらった。みをは、CODHが開発したくずし字認識モデルKuroNet、およびKaggleくずし字認識コンペで1位となったtascj氏が開発したくずし字認識モデルを用い、国文学研究資料館が作成しCODHが公開する日本古典籍くずし字データセットを活用している。iOSとAndroid向けのアプリを提供している。これがあれば、古い文書の解読には鬼に金棒だ。(出典:みを)
80:20の法則と精度100%への道
AIと人間がどのように協力し合うかは悩ましい。上位2割を網羅すればほぼ8割の成果が得られるという80:20の法則が有名だが、この場合にAIが80%の成果を達成し、残り20%の精度を高めるために人間が間違い探しをコツコツと対応するのは悲しい。そうではなく、人が楽になるように、AIに任せられる作業はAIに切り出して全体の作業を効率化したい。
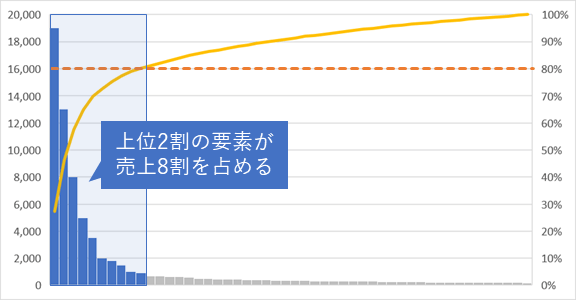
(出典:シマウマ用語集)
最善主義と完璧主義
AIと人間の効率的な分担を考える場合には、最善主義が望ましい。失敗を許容しない完璧主義や、完璧主義を求められる業務にはAIの活用は難しい。そうではなく、ある程度の失敗は受け入れるが、同時に成功も受け入れる。AIの活用を通じて徐々に精度を高めていけばいいじゃないかというような文化のある業務は意外と少ないけど、そのような業務にこそAI利用は進化を発揮するのだと思う。

(出典:私立大学退職金財団)
顔コレデータセットの活用
IIIFとは
IIIE(トリプルアイエフ)とは、International Image Interoperability Frameworkの略だ。IIIFは国際的な画像配信方法だ。WEBのHTMLに相当するものが画像のIIIFだという。IIIFでは、画像を記述しウェブ上で配信するための標準的な方法を提供するいくつかのアプリケーションプログラミングインタフェースと、構造化された画像シーケンスに関するプレゼンテーションベースメタデータを定義する。構造メタデータはシーケンスに関するプレゼンテーションベースメタデータを定義する。美術品、書籍、新聞、原稿、地図、巻物、一点物のコレクション、アーカイブ資料などを保有する機関が、そのコンテンツのために IIIF エンドポイントを提供すれば、IIIF に準拠した視聴者やアプリケーションは、消費と表示のために画像とその構造および提示メタデータの両方を利用することができる。IIIFはクライアントとサーバの両方で共有技術を育成し、リポジトリ間の相互運用性を実現するとともに、互換性のあるサーバや閲覧アプリケーションの市場を育成することを目的としている。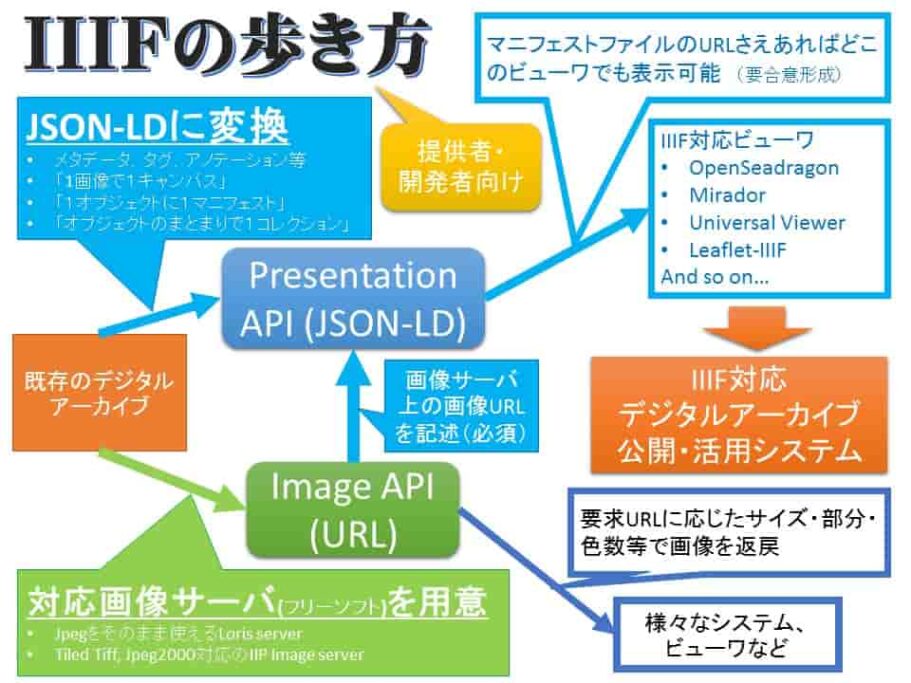
(出典:Hatena blog)
キュレーションとは
キュレーション(curation)とは、元々はノリとハサミを使って行う資料の収集や作品の展示などの活動を意味する。現在のネットで使われるキュレーションはデジタルキュレーションだ。インターネット上にある膨大なコンテンツや商品の中から独自の基準で選別・編集などを行う。デジタルキュレーションでは、デジタル資産の選択、保存、維持、収集、アーカイブなどを行う。現在および将来の使用のために、デジタルデータのリポジトリを確立し、維持し、追加する。デジタル・キュレーションを成功させることで、デジタル・オブセッションを緩和し、ユーザーが無期限に情報にアクセスできるようになる。

(出典:富士通)
メタデータによる顔貌比較
膨大な写真から顔の部分を切り取り、顔貌コレクション(顔コレ)を構築することで顔貌比較が可能となる。下の写真は、アイドルのえなこの写真だ。beforeとafterと書かれているが、確かによく似ているけどかなり進化している。顔貌比較のツールを用いることによって美術作品などの網羅的な分析も可能となる。

(出典:TOPIC BOX)
歴史的資料、史料の活用
過去には地震や噴火や気候、疾病に関する各種文献が残っている。また、経済、人口、政治、文化に関する各種人文社会的データも不完全ではあるが残っている。これらを歴史ビッグデータとして活用しようというのが歴史ビッグデータの統合解析だ。歴史書類から得られた情報をもとに未来につながる知恵を抽出したいものだ。

(出典:NII)
江戸切絵図から探す
日光江戸村にいけば、江戸時代を味わうことが可能だ。しかし、近年のARやメタバースなどの技術を活用すれば、サイバーの世界でバーチャルに江戸の街並みや江戸の生活、風情を楽しむことも可能だろう。歴史を探訪することがビジネスにつながるという期待感が強い。
(出典:江戸の名所)
Time Machine Europe
ヨーロッパの文化的な遺産をデジタル化・構造化し、誰もがアクセスできるビッグデータを構築するという構想がTime Machine Europe(TMプロジェクト)だ。欧州委員会のフラッグシップ研究計画として、10年で1000億円の投資が検討されている(参考)。 このプロジェクトは,元々はスイス連邦工科大学ローザンヌ校(EPFL)のカプラン(Frédéric Kaplan)氏が2012年に開始した構想だが、メディアで話題になり、アムステルダムやパリなど欧州の他の都市でも同様の試みがローカルTMとして広がった。2020年2月現在,プロジェクトは600以上の機関,6,000人以上の専門家が関わっている。欧州は1000年の歴史を誇るが、日本は万年の歴史を持っている。日本でも同様にプロジェクトが全国で沸き起こると将来に夢が持てると思う。

(出典:PCGameBenchmark)
武鑑全集の構造化
武鑑とは、江戸の大名や家臣に関するデータブックであり、現在の四季報のようなものだ。江戸時代の約200年に渡り出版され続けたベストセラーだ。役職移動情報や江戸観光土産、大名行列閲覧ガイドなども含まれている。情報更新は多い時には月に数回実施されていたようだ。これは素晴らしい情報の宝庫だ。戦争や関東大震災などで消滅したものもあるが、難を逃れたものは日本国の宝だと思う。
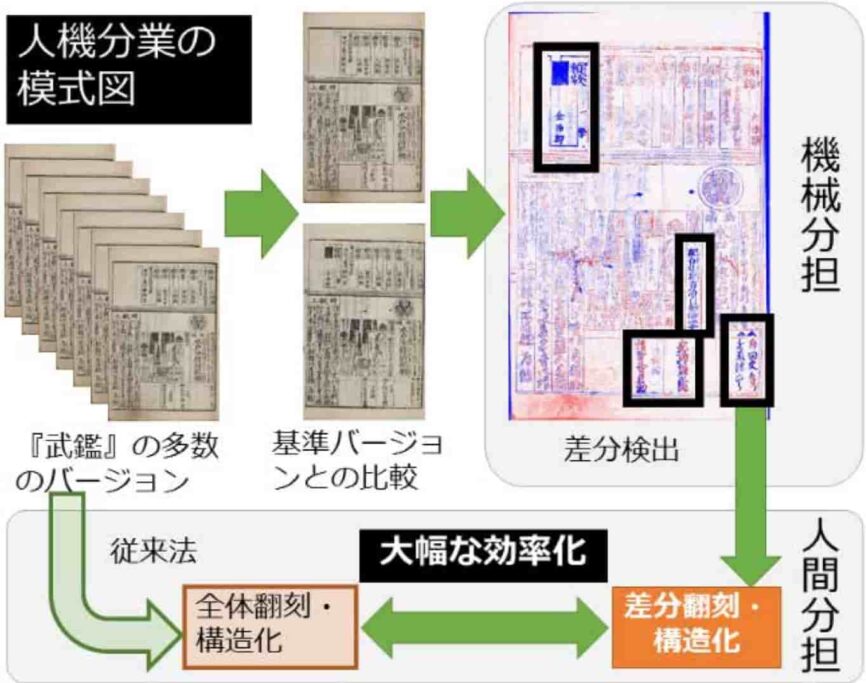
(出典:agora)
まとめ
デジタルの力で人文学を推進するのは、人文学の専門家にとっても、情報系の専門家にとってもメリットがあるし、利用者や国民にとってもメリットがある。AIの技術を用いて古代の神代文字などの解析ができないものかと思い、質問した。確かに、全く解読されていない古代の文字の解析は厳しいかもしれないが、部分的には判明している文字や、解読されている文字の検証などには有効かもしれないと思った。また、個人的には縄文人とシュメール人の関係や古代イスラエル人と渡来人の関係などにも興味があるけど、遺伝子のデータなどを解析したり、土器や言語、ペット、食料、風習などのまさに人文学的なデータがどんどんデジタル化してオープンになれば、新たな真実が見えてくるかもしれないと思った。呉越同舟ではないけど、文系と理系の専門家が協力して研究を進め、成果を上げられることができれば素晴らしいと思うし、自分も何かに貢献したいと思った。
以上
最後まで読んで頂きありがとうございました。
拝


