
はじめに
前回は、AIとゲームのその1として完全情報ゲームについて気になるキーワードなどを解説した。今回は深層強化学習と非完全情報ゲームについてまとめたい。
AIとゲーム(その1):完全情報ゲームを考える。 (前回の投稿)
AIとゲーム(その2):深層強化学習、非完全情報ゲーム (⇨ 今回の投稿)
深層強化学習
深層学習と強化学習を合わせると深層強化学習となる。強化学習とは、ある環境下に置かれたエージェントが環境に対して行動をし、得られる報酬が最大化されるような方策を求める機械学習アルゴリズムである。環境がエージェントに更新された状態と報酬を与える。エージェントは報酬をもとに行動の方策を修正し、1に戻るといったサイクルを通じて性能を高める手法だ。エージェントが環境に対して行動を起こし、環境が状態の更新と行動の評価を行い、状態と報酬をエージェントに知らせるというサイクルを回して学習が進む。得られる報酬の合計が最大化されるように、行動価値関数と方策を学習によって最適化する。
(出典:Avinton)
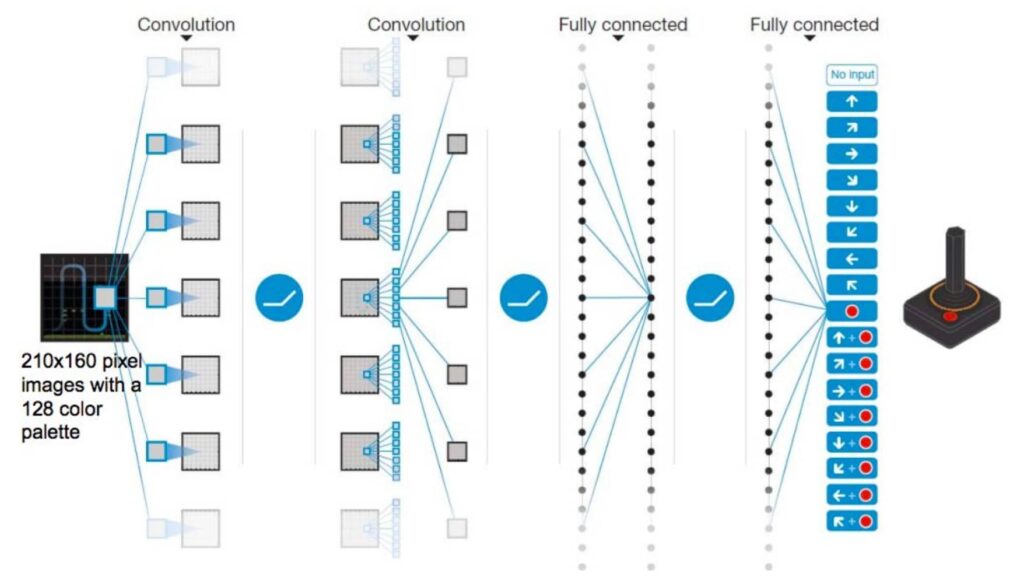
Deep Q-Network
深層強化学習とは強化学習と深層学習の手法を組み合わせた概念だが、代表的な手法はDeep-Q-Network(以下、「DQN」という)だ。DQNはQ学習における行動価値関数(Q関数)を、畳み込みニューラルネットワークに置き換えて近似する。Q学習では、状態数 s × 行動数 a のテーブルを更新することによってQ関数を更新する。しかし、状態数が大きくなってくると、テーブルによってQ関数を表すことが現実的ではなくなってくる。このため、Q関数を畳み込みニューラルネットワークで表現するアプローチをとり、学習が収束するための工夫をしたものがDeep Q Networkだ。
(出典:Avinton)
マルコフ決定過程
マルコフ決定過程(Markov Decision Process:MDP)とは確率過程の一種で、現在の状態とその時の行動結果から確率論的に将来の状態を決定し、 かつ行動結果に対して報酬を紐づける状態遷移モデルで、以下式で表す。MDPとマルコフ過程の違いは、MDPはマルコフ過程に対して行動と報酬の概念が加わっている。ゴルフを具体例に説明します。以下がMDPの状態遷移図になります。ゴルフボールのある位置を「状態」、打つクラブの種類を「行動」とします。ティーグラウンドから開始し、ドライバかアイアンを選択して打ちます。 どちらを選択するかを決める考え方の事を方策(Policy)という。状態が決まったらアクションが一意に決まることを決定論的方策(Deterministic Policy)といい、確率的にアクションが変わることを確率論的方策(Stochastic Policy)と言う。


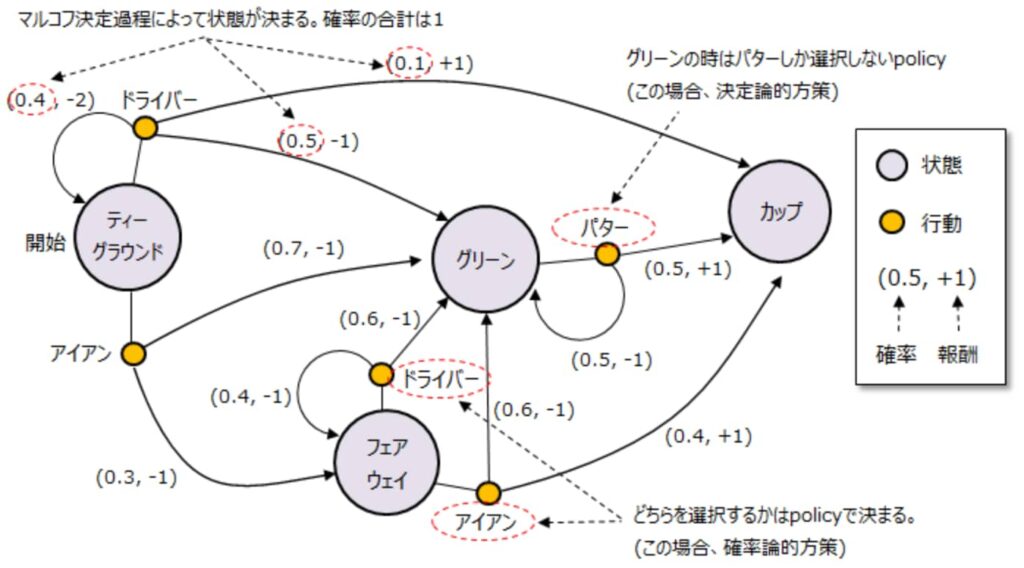 (出典:制御工学の基礎)
(出典:制御工学の基礎)
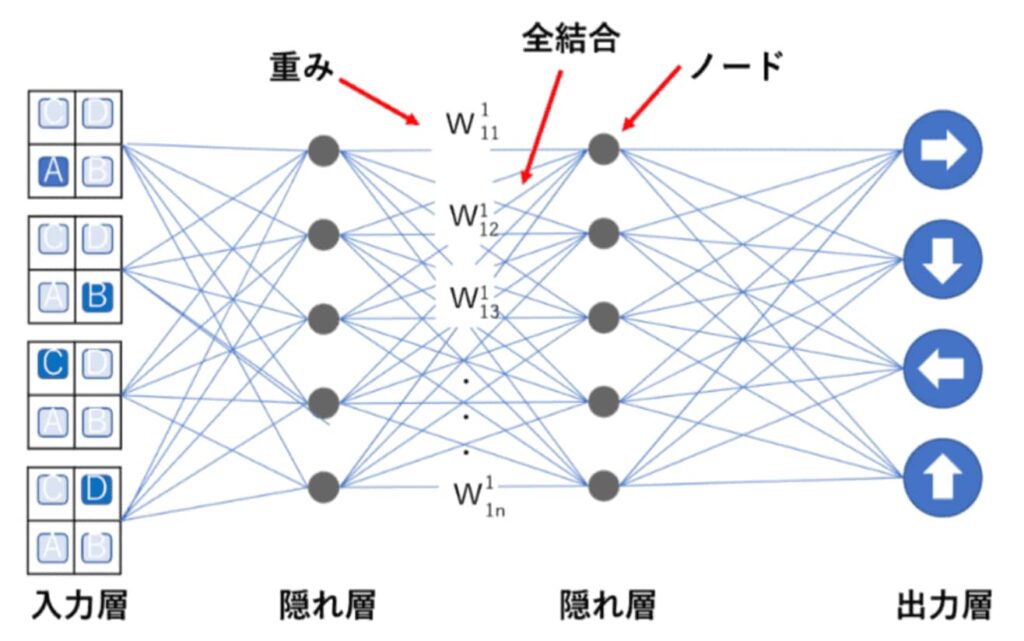
行動価値観数
状態価値関数Vπ(s)Vπ(s)は、状態ssが持つ価値を表す。各状態の価値が分かれば、その状態を選ぶ行動がベストな行動である。Vπ(s)Vπ(s)は、変数に行動aaを持っておらず、直接取るべき行動が示されているわけではない。一方、行動価値関数は、状態ssでの行動aaを評価する関数であり、ある状態ssが与えられたとき、どの行動が最適な行動なのかを知る。
状態価値関数Vπ(s)Vπ(s):状態ssにあるときに、方策ππに従ったときの価値
行動価値関数Qπ(s,a)Qπ(s,a):状態ssにおいて行動aaを取った後方策ππに従ったときの価値
Qπ(s,a)Qπ(s,a)を定式化する。仮定は次の3つ。方策ππが決まっている。現在の時刻ttでは、方策ππに従わず、行動aaを取り時刻t+1t+1で状態s′s′に遷移する。時刻t+1t+1後の行動は、方策ππに従って行動する。
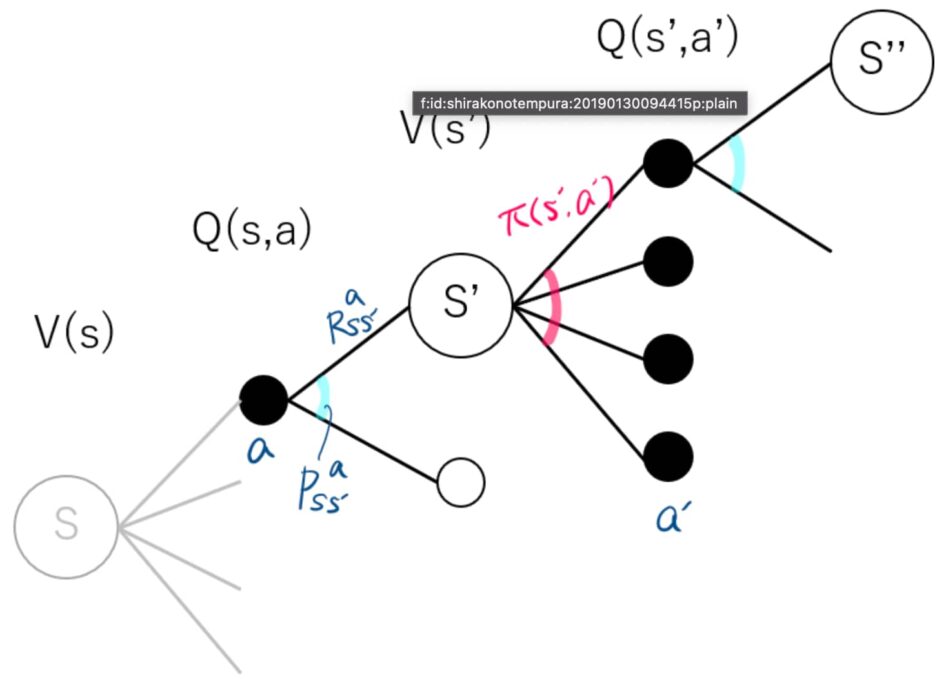
(出典:Hatena Blog)
非完全情報ゲーム
ゲームでは、完全情報ゲームと不完全情報ゲーム、運が絡む不確定要素の有無、そして二人か多人数かによって分類したものを下の図に示す。AIがプロ棋士を凌駕したものは、実は完全情報で二人で行う確定ゲームだった。今後は、難易度の高い、不確定で他人数で行う不完全情報ゲームへの応用が期待される。例えば、大勢で行うトランプゲームなどはゲームのカテゴリーからいえば難易度は高い。
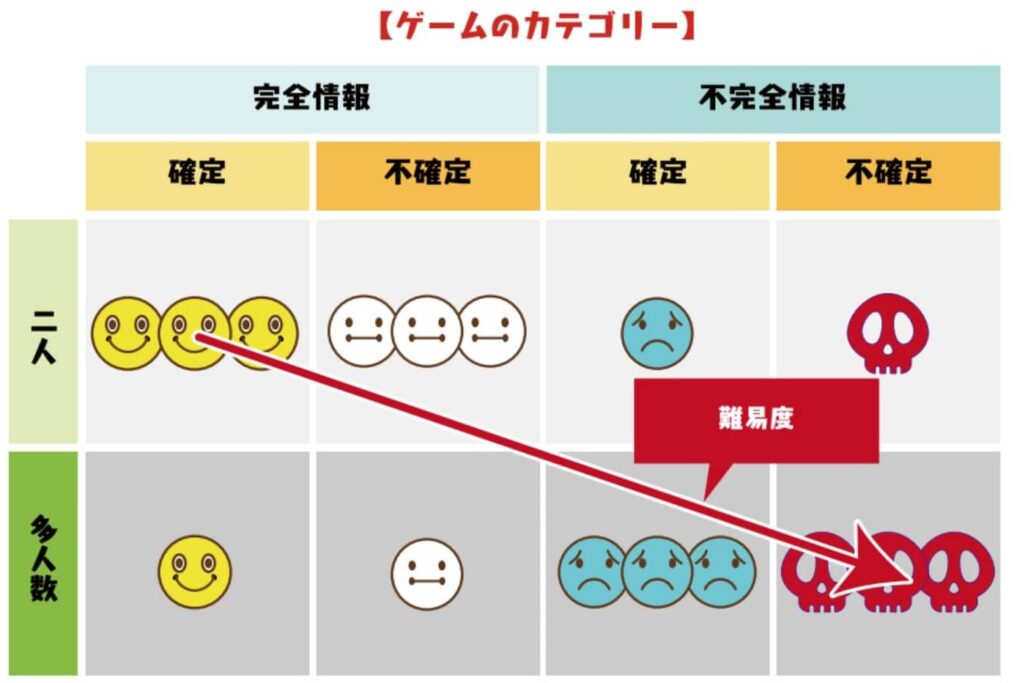
(出典:Game Biz)
コンピュータポーカーの進歩
ポーカーは、複数の参加者が配られたトランプカードを見ながら、参加者の手札を想像しながら、次のカードを要求したり、勝負に賭けたりする。カナダ・アルバータ大などのチームは、AI技術を駆使して、ポーカーのプロを相手に圧勝するコンピューターソフト「ディープスタック」を公開した。ポーカーでは相手の手札が見えず、展開を読むのが難しいが、勝つための直感を磨いたという。ゲームでは、各自2枚ずつ配られた相手に見せない手札と、テーブルに広げた5枚の共通札とを組み合わせ、段階的に賭けるチップを増やしながら役の強さを競う。ディープスタックは1千万を超えるゲームの展開を深層学習技術で学び、人間でいう局面ごとの直感を磨いた。1対1ではなく大勢の人が参加するポーカーでは格段に複雑度が増す。
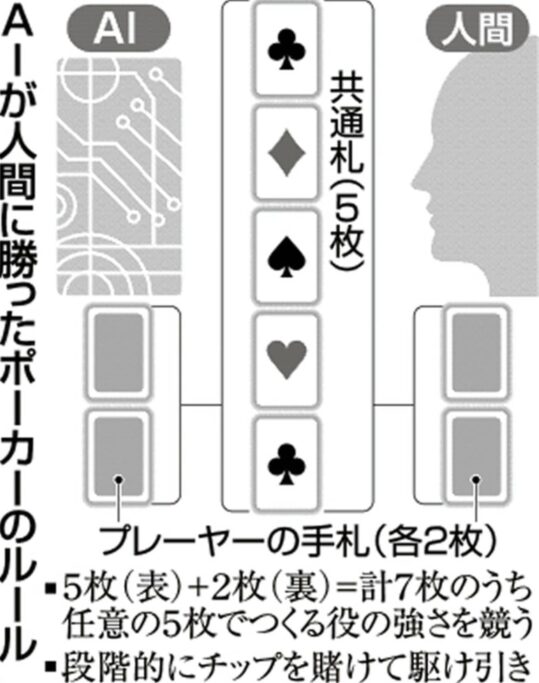
(出典:日本経済新聞)
ナッシュ均衡
ナッシュ均衡(Nash equilibrium)とは、他のプレーヤーの戦略を所与とした場合、どのプレーヤーも自分の戦略を変更することによってより高い利得を得ることができない戦略の組み合わせである。ノーベル賞受賞者のジョン・ナッシュ(John. Nash)が提唱した。ナッシュ均衡の下では、どのプレーヤーも戦略を変更する誘因を持たない。下の図は、利得表と呼ばれる。生産量の増産あるいは現状維持を考える。相手企業の戦略は分からない状況です。この条件での競争を「クールノー競争」と言う。このペイオフマトリックスでA社が取る戦略は増産以外にありません。もしB社が現状維持を選んだ場合、A社の売上は最高になり、仮にB社が増産しても現状の15億円より2億円アップした17億円になる。B社の戦略に関係なく、A社は増産しか選択肢がない状態のことを支配戦略と呼ぶ。一方、B社の立場で考えても増産となります。この結果、両社共に増産を行うことになり、市場価格は値崩れを起こす。望む最高の結果にはならないので「囚人のジレンマ」と呼ぶ。コンビニ業界が陥っているジレンマだ。相手がどうあろうと両方とも増産に走るため、シナリオ4の状態に収斂することを「ナッシュ均衡」と言う。
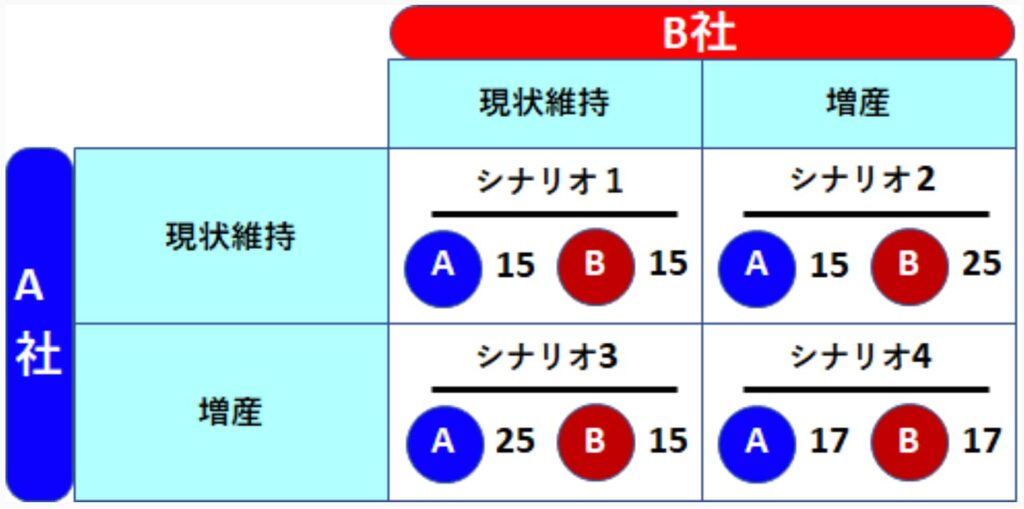
(出典:News)
学生からの質問
自分を含めて、講義の後半には質問がいくつか出された。
心理戦を機械学習で上達することはあるか?
囲碁や将棋では心理戦を考える必要はない。しかし、ポーカーや麻雀などの非完全情報ゲームでは、相手の行動パターンや心理状況などを分析する。つまり、心理戦の極意をマスターすることで実力を伸ばすので、答えはYESだ。これは自分からの質問だった。
弱い手でベットし、強い手でベットしない理由は?
一見、不合理な行動のように見えるが、このように行動することにいは意味がある。つまり、強い手では必ずベットして、弱い手では必ずベットしないという行動は予測しやすい。つまり、ゲームの相手としては持ち札を類推されやすい。このため、わざと手札の実力とは異なる行動をとって相手を撹乱させる行動が有効となり得る。いわばハッタリの勝負も有効なケースがあると言うことだ。
教師となる報酬が得られればQ学習が可能か?
AlphaStarはかなり強い。AlphaStarはゲームのプレイ方法を模倣学習することで学ぶ。スタークラフトの開発元が匿名にして提供した膨大な数のリプレイ動画約50万をひたすら観戦する。その次には、AIエージェント同士を戦わせる。エージェントたちは「このユニットを使って勝つこと」「この敵に特化して戦うこと」といった異なる学習目標が与えられる。エージェントは互いに戦うことによって新しい戦法に出合い、それに対抗する戦術を生む。約1週間続けた結果、経験豊富なエージェントの200年分の試合を実践したという。
まとめ
AlphaStarが上達したようなスキームは、実はF1レーシングでも、カーリングでも、ゴルフでもさまざまなプレイの様子を観察させ、次にエージェント通しで競わせて、数百年分の試合を1週間でこなすと経験豊富なAIプレーヤを育てることができるだろう。人間は、そのAIプレーヤと戦い、そのAIプレーヤから学ぶことによってこれまでとは異なる異次元の成長を図ることができるのではないか。そんなことがさまざまな分野で実践されるとすると、AIを使いこなる人間とそうでない人間では実力に雲泥の差が生じることになる。その意味では貧富の差はこれからもさらに広がってしまうだろうし、それをどのように是正するのかは人間の良心と知恵に委ねられているのかもしれない。
以上
最後まで読んでいただきありがとうございました。
拝


