
はじめに
前々回と前回の二回に渡り、GCL特別講座の第9回の講義で拝聴して気になったキーワードをネットや文献で調べて自分なりにまとめてみた。今回は、最後の三回目だ。これからのAIとそれにより見えてくる可能性についてまとめてみたい。
その1:LINEにおけるAI研究とビジネス化 (前々回の投稿)
その2: LINEの大規模AIモデルに向けて (前回の投稿)
その3:これからのAIと見えてくる可能性 (⇨ 今回の投稿)
大規模言語モデルにおける汎用事前学習の開発競争
自然言語処理(NLP:natural language processing)の技術革新はめざましい。NLPの事前学習用にGoogleが2018年に開発した変換器ベースの機械学習技術がBERT(Bidirectional Encoder Representations from Transformers)だ。Googleは、2018年の発表に続いて、2019年には検索エンジンにBERTを活用すると発表し、2020年後半にはほぼすべての英語のクエリにBERTを使用した。英語版BERTは、(1) BERTBASE:12個のエンコーダと12個の双方向自己アテンションヘッド、(2) BERTLARGE:24個のエンコーダと16個の双方向自己アテンションヘッドの2モデルだ。両モデルとも、8億語のBooksCorpusと2500万語の英語版のWikipediaから抽出したラベル無しデータから事前に学習しているという。
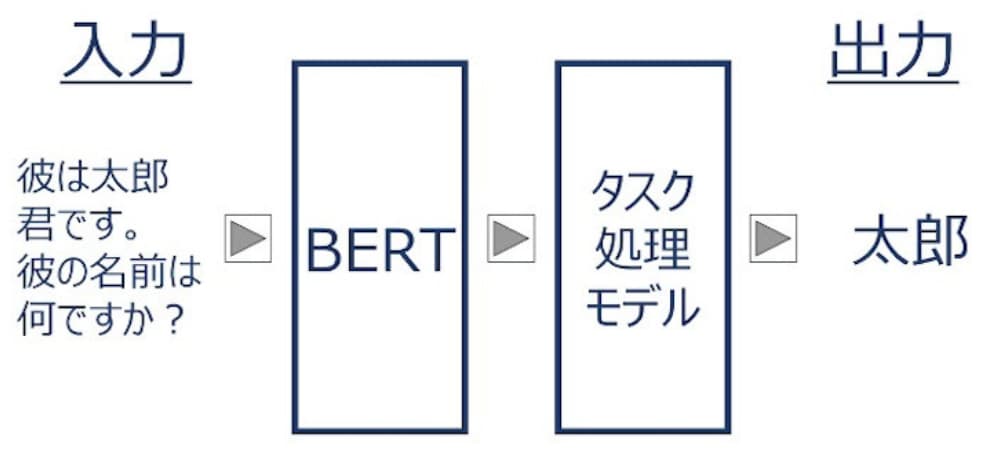
(出典:Ledge Ai)
解説から俳句を生成するプロンプティング
AIの実力は日々進化している。例えば、ある俳句とその解説を教師データとして教え込むと、解説から俳句を作ってしまうという。これにはプレバトの夏井いつき先生もびっくりかもしれない。そのうち、名人への挑戦を人間とAIが競うなんていう場面がテレビで見れるようになるのかもしれない。このAIによる俳句の良いところは、気に入らなければ何度でもやり直しを命じることができることだ。俳句を作るAIと創作された俳句を評価するAIが高速でトライアンドエラーを何百回、何万回、何億回と繰り返したら、そのうち人間もびっくりするような作品ができるだろう。しかし、人間とAIが競争するという図式で捉えるのではなく、人間がAIを活用してトレーニングするという図式で捉えた方が前向きかもしれない。

(出典:Logmi)
商品解説文からキャッチコピーを生成するプロンプティング
同じような構図から、例えば、売りたい商品の特徴の解説文から、売れるキャッチコピーを生成するAIもあり得る。通信販売のジャパネットタカタの高田社長のようなトーク力に成長するかどうかは疑問だけど、原理としてはかなり高度なレベルまでの実力を磨くことはできそうだ。実際、ネットでキャッチコピー・AIで検索すると、AIによるコピーでCVRが43%や59%と大幅にアップした事例が紹介されていた。CVRはConversion Rateの略で、Webサイトへのアクセス数のうち実際の商品購入などのコンバージョンに至った割合である。
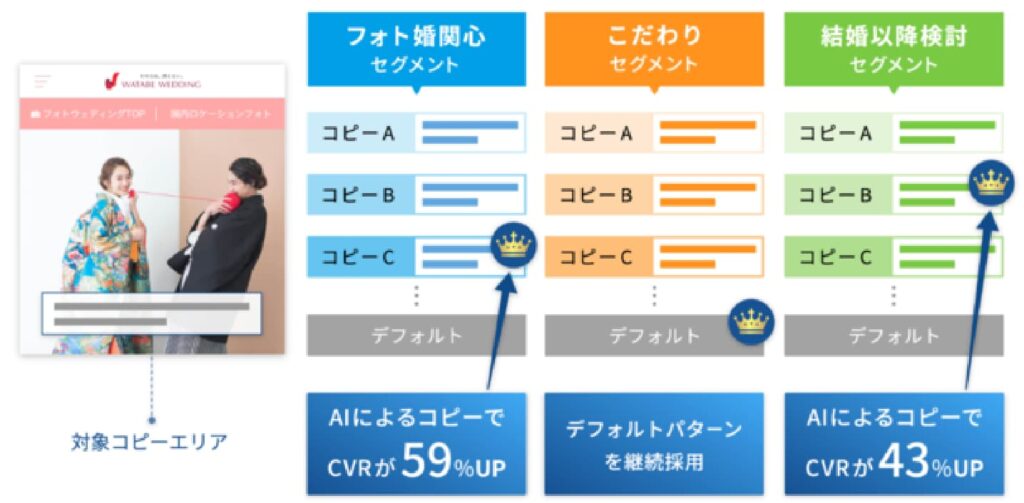
(出典:PR Times)
メモ文から営業日報を自動生成するプロンプティング
例えばある現場で作業をしてその日報を自動生成するAIもあり得るだろう。これがうまくいけば、必要な情報を入力して、あとは現場の写真や動画を格納しておけば、AIがそれらのデータを咀嚼して、営業日報や現場作業日報のようなドキュメントに仕上げることも可能かもしれない。ここまでくると超優秀な秘書のような感じだ。
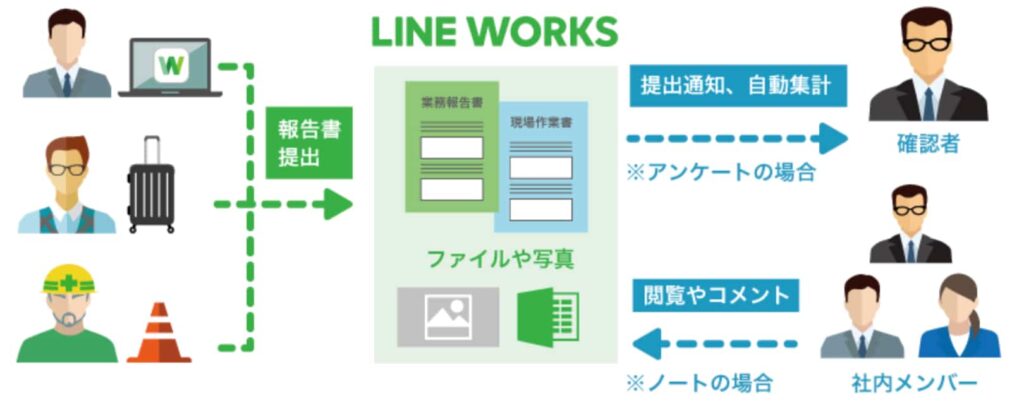
(出典:LINE WORKS)
考え方を教えることで推論精度を高めるプロンプティング
一般にAIは答えを導くことはできるけど説明できない。このため、説明可能なAIの研究が進んでいることを以前投稿した。Google ResearchのBrainチームでは、下の図(左)のような標準的な処理プロンプトを改良して、下の図(右)のように処理のステップを説明して答えを導き出す「Chain of Thought Prompting」を開発した(出典)。副次的な効果として、標準プロプトでは正解を得られなかったケースも、改良プロンプトでは正しい答えを得ている。このように解答までのプロセスが見える化すれば、必要に応じて前提条件を変えることもできるし、処理のロジックの正当性を確認することもできる。このモデルでは、言語モデルの推論能力を向上させるためのプロンプト作成方法を検討する。多段階の問題を中間段階に分解する思考連鎖プロンプトを用いることで、パラメータ数が100億個までの大規模言語モデルなら標準的なプロンプト手法では解けない複雑な推論問題を解くことができると言う。これは素晴らしい。
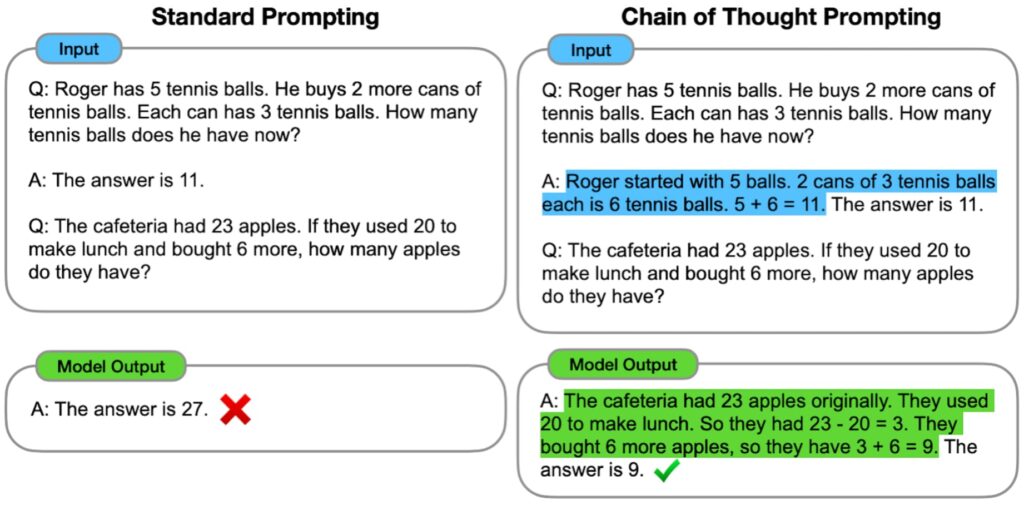
(出典:Google AI Blog)
目的志向特化型AIの先に見える汎用AI
MiLAIとは、Mixed LINE AIの略だ。最後の最後になってから井尻さんがまとめられているサイトが見つかった。井尻さんのお話を聞きたい人はこのサイトをアクセスすれば、音声の再生や、井尻さんが解説する動画も見つかった。ズバリこの動画を見るだけで目から鱗になるだろう(笑)。
(出典:Logmi)
今後の課題
Vision and Language
マルチモーダルとは、画像とテキストのエンコードの対から対照学習を行うことで双方の共通の埋め込み空間を学習する仕組みだ。モーダルとは様式のことなので、マルチモーダルは視覚や聴覚、臭覚、触覚などの複数のコミュニケーションモードを利用して理解を深めることを志向している。その中でも注目されているのが、テキストと画像の連携だ。つまり、画像からテキストを生成したり、テキストから画像を生成する。サンプル数が増えるほどに、スケーリング法則に基づいて精度が向上すると期待される。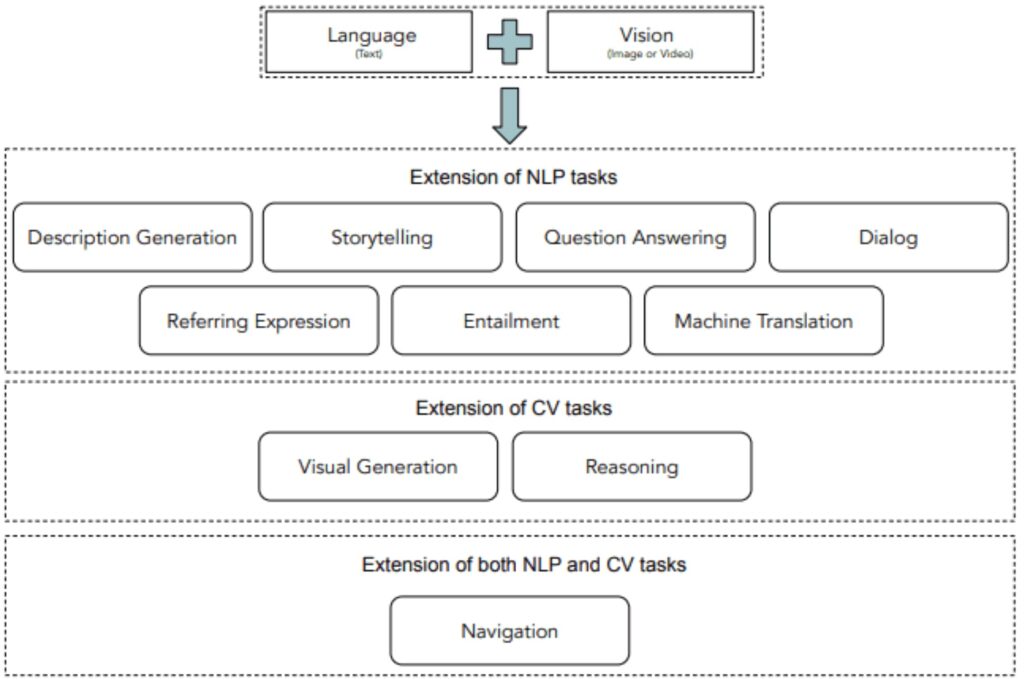
(出典:AI Summer)
Visual Language Model(VLM)
視覚言語モデリング(Visual Language Model、以下「VLM」という)は、対応する視覚入力に言語理解を根拠づけるものだ。例えば、下の図の画面に対して、簡単な接頭辞(Prefix)を与えて、自然言語的な説明文を生成することにGoogleは成功している。このようなクロスモーダルな作業は課題も多く、既存の視覚言語事前学習(vision-language pre-training、以下「VLP」という)では、設計に時間がかかり、スケーラビリティも低かったが、SimVLM(Simple Visual Language Model Pre-training with Weak Supervision)などの新しい手法では、言語モデリングに似た統一的な手法で学習に成功している。日本語と英語という異なる言語の翻訳は、非常に難しい課題であったが、現在では既に実用的なレベルで利用できている。同様に言語と画像の翻訳もこれから急速に進歩すると期待されている。さらに言えば、ロボットの動作や、自動運転の車両の動きと映像とテキストの翻訳が進めば、赤信号を見て、停止して、「止まります」発声するだけでなく、桜の開花時期になったら、お勧めのスポットを紹介して、そこに移動するなんてことも視野に入ってくるだろう。

(出典:Google AI Blog)
汎用AI(AGI)の可能性
強いAIと弱いAIという議論がある。個人的には、対象の幅と推論の深さで二次元に分類する考え方が好きだ。現在は、特定の機能を想定した浅い処理のAIかもしれない。しかし、今後はさまざまな機能に対応する汎用型に進むと同時に、システムの処理の高度化やアルゴリズムの改善により推論のレベルも深くなる。どのAIが良いとか悪いとかではなく、さまざまな用途に応じて、さまざまなAIを使いこなす時代になるように思う。弱いAIを狭い(Narrow)AI、強いAIを汎用的なAI(AGI:artificial general intelligence)と呼ぶ。世界の主要なIT企業や政府・大学などの研究機関においてAGIの研究が進められている。下の図は2017年に発表されたもので、倫理、リスク、政策の観点から、世界中から45のプロジェクトを特定し、マッピングしたものだ。講義ではAGI survey 2020が紹介されていたが、ネットでは見当たらず、また大きな変化はないので、2017年版を引用しておく。論文も参考になる。日本のプロジェクトとしては、Whole Brain Architecuture Initiativeがノミネートされている。このマップにLINEのプロジェクトが取り上げられるのは時間の問題だろう。
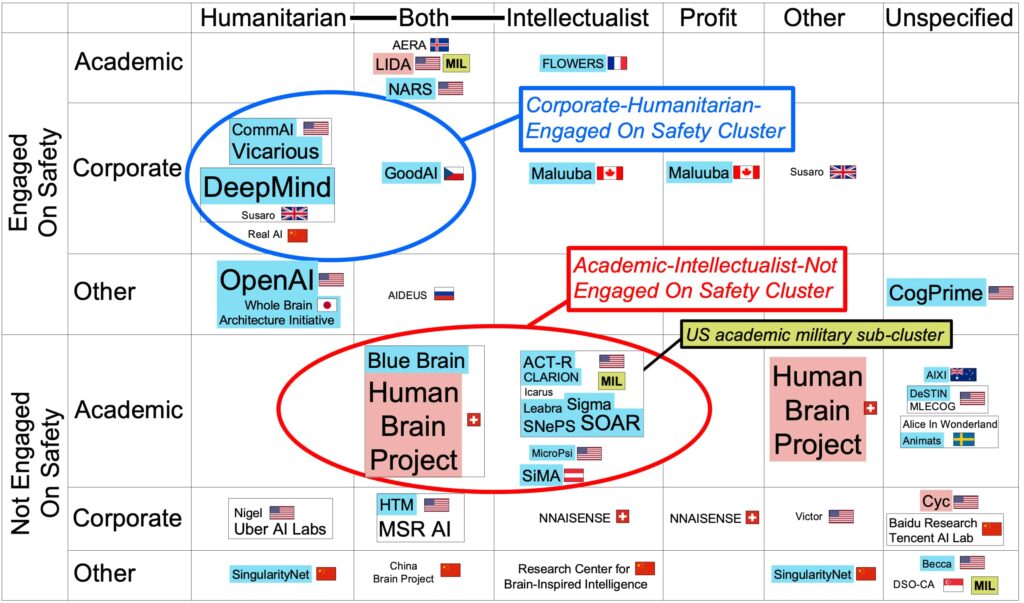
(出典:SSRN)
まとめ
これまで3回にわたってLINEの井尻講師の講義を拝聴して気になったキーワードを中心にネットや文献で調べてまとめてみた。これだけ書いてもまだ講義で触れられた内容の半分にも満たないほど講義は充実していた。また、特に最後の言語と画像の翻訳や、視覚言語モデリングなどはまさに日進月歩の研究が進められている。深層学習のメカニズムを活用して囲碁や将棋、言語翻訳にとどまらず、言語と画像の翻訳や解説文から俳句を作ったり、商品の写真からキャッチコピーを生成したりといったことまでできるとは正直驚いた。しかし、AI関連の技術革新は、これからも継続的かつ指数関数的に加速すると予想される。AIに負けないように人間も進化する必要があるけど、AIを活用する藤井聡太棋士が活躍するように、AIの進化は人間の進化を促す側面もある。自分のライフワークは安全・安心だ。先日参加した労働安全コンサルタントの研修での法規では、記録を磁気テープで保存し、ファクシミリなどを使って伝送などという記載があり、苦笑してしまった。安全・安心を高める分野にもAIの機能を活用して改善することは今後増えてくるだろう。今回、受講した内容を聞いただけで終わらせるのではなく、実際の業務に活用できるように引き続き研鑽したいと思う。毎週金曜日の夕方に開催されたメディア論も残すところあと一回だけど、これまでの講義については全てブログにまとめることができた。内容は事前に各講師の方々にも見てもらい、皆さんから快諾いただけた。今回の井尻さんからは多くの指摘や示唆も頂きました。ありがとうございました。非常に興味深い講義を拝聴できたことに関係者に感謝します。
以上
最後まで読んで頂きありがとうございました。
拝
参考:これまでのメディア論のブログ歴
第1回:初回受講はワクワク感しかない
第2回:メタバースで変わるビジネス
第3回:世界を変えるLive to earn
第4回:スクエアエニックス 橋本真司氏の講演
第5回:MSの畠山大有氏のサステナブル概略
第6回:メルペイの可能性とその先
第7回:ネット広告の現状とサイバーエージェントの躍進(その1、その2)
第8回:ソフトウェアの脆弱性(その1、その2、その3)
第9回:LINEの大規模AIモデル(その1、その2、その3)


