
はじめに
今日は脳がどのように言葉を処理するのかという動画を視聴した。國吉教授の授業で脳の構造や仕組みはかなり勉強したので、今回は理解しやすかった。興味のある方は是非視聴してみて欲しい。
(出典:YouTube)
言葉は脳の中でどのように処理されるのか
脳でどのように処理しているのかを簡単に説明するのは意外と難しい。そもそも日本人と西洋人では音を認知する左右の脳の分担が違っているという説もある。日本人も西洋人も右脳で音楽を聴き、左脳で言語を聞くのは同じだけど、下の図に赤字で示すように感情音やハミング音では使用する部位が異なるようだ。
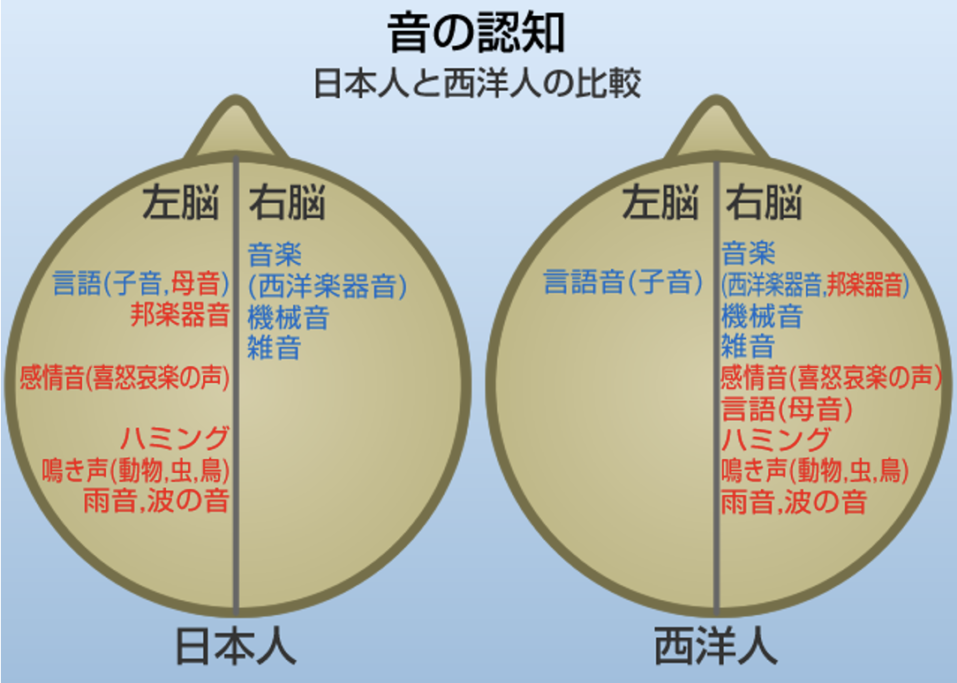
(出典:onosokki)
単語と文脈
これは動画の中でも語られていたが、ランダムに並んだ単語を聞くよりも、文脈を持った文章を理解する方が処理が速く進む。同様に単語を覚えるよりも文章を覚える方が優しいし、活用しやすい。それは人間は単語の音を聴きながら文脈をベースに推論を働かせながら単語を予測しながら聞いているためだ。クイズで答えを焦らされると、もう知りたくてたまらなくなるけど、これも脳の理解の仕組みと関係しそうな気がする。
同音異義語や複数の意味をもつ単語
同音異義語(homophones)や複数の意味をもつ単語は日本語にもあるし、英語など他の言語にもある。でも日本語は同音異義語がとても多いが、これは音の最小単位である音節が英語は3,000以上あるけど、日本語は100ほどしかないためだという(出典)。

(出典:時空先生)
オノマトペ
動画から離れるけど、日本語の特殊性の一つはオノマトペだ。オノマトペとは、フランス語の”onomatopée(擬音語)”からの外来語だけど、世界の言語の中でも日本語は突出してオノマトペが多い。具体的には、下の図にあるような擬音語、擬声語、擬態語、擬用語、擬情語などだ。英語ではこれに1対1で対応する言葉がまずない。せいぜいmimeticとonomatopeだ。日本語では、数の数え方もいち、にー、さん、ヒーフーミー、ひとつ・ふたつ・みっつと多彩だ。以前、カタカムナについて投稿したが、その中でヒーフーミーが含まれていた。
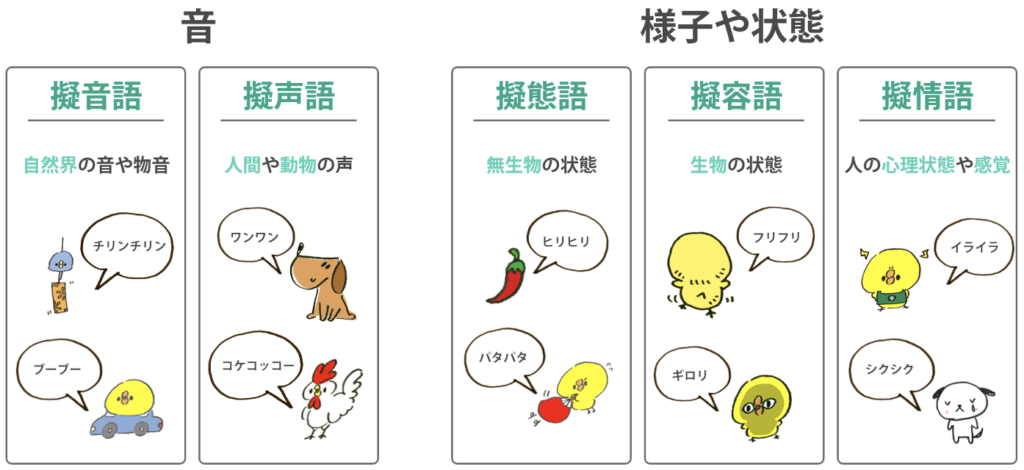
(出典:agex)
8つの質問
この動画に戻ろう。動画を視聴すると8つの質問が待っていた。
Q1) When we listen to speech, how often do we identify the correct word?
答えは98%だ。動画の最初で、脳は言葉を聞くたびに何千もの選択肢の中からマッチングさせ、98%の確率で正しい単語を選択すると説明があった。
Q2) Which of the following doesn’t helps us to recognize words quickly?
音の意味を理解するために脳は平衡的な処理を行うとあった。大きな声で話すという説明はなかったので、”Speaking louder”だ。
Q3) When does the brain start to access the meaning of a word during speech comprehension?
音を聞きながら文脈をベースにして単語を聞き分けるので、”Before the word is identified”だろう。
Q4) On average, how often do adults learn a new word?
大人は数日おきに新しい単語に出会うと説明していた。自分はもっと多い気がする。
Q5) Which part of the brain helps us to learn new words?
短期記憶は海馬(hippocampus)が担い、長期記憶は大脳皮質(coretex)が担う。
Q6) When we recognize speech, what is the advantage of having processing units that are dedicated to the recognition of just one word?
一つの意味しかない単語であれば脳の処理はシンプルになる。しかし、実際には限られた音節を組み合わせるので同音異義語や単語だけど異なる意味を持つ単語などもあり、どれだろうと悩むことになる。英語で説明すると次のような感じだろうか。
Q7) Would recognition of written words operate in the same way as for spoken words?
書き言葉の理解と聞き言葉の理解は全くプロセスが異なる。TOEFLの試験でもリーディングはマシだったけど、リスニングは酷かった(涙)。英語で説明すると次のような感じだろうか。
Q8) How does sleep help us to learn new words?
これは難しい質問だけど、動画の説明に沿えば次のような感じだろうか。
まとめ
言葉は会話から始まり、それを記録したり、人に伝えるために文字ができて書いたり読んだりするようになったと考えるのが自然だろう。つまり、言葉の基本は口語だ。そして、日本には古くからいくつかの種類の交互があったのだと思う。漢字が日本に伝わるまで日本には文字がなかったというのは、ちょっと疑問だ。以前も投稿したけど、ざっと調べるだけでも、「神代文字、アナイチ文字、ヲシテ文字、サンカ文字、豊国文字、カタカムナ文字」などがある。特にカタカムナ文字は、カタカナの原型ではないかと思われるほど類似している。これらの存在をないものにして、日本には文字はなかったとなぜ断言できるのかが理解できない。話を動画に戻すと、やはりこのような高度な処理をするための言語脳を鍛えることが特にリスニング力の強化のためには必要なことと再認識した。
以上
最後まで読んで頂きありがとうございました。
拝
参考:英文スクリプト
The average 20 year old knows between 27,000 and 52,000 different words. By age 60, that number averages between 35,000 and 56,000. Spoken out oud, most of these words last less than a second. So with every word, the brain has a quick decision to make: Which of those thousands of options matches the signal? About 98% of the time, the brain chooses the correct word.
But how?
Speech comprehension is different from reading comprehension, but it is similar to sign language comprehension – though spoken word recognition has been studied more than sign language. The key to our ability to understand speech is the brain’s role as a parallel processor, meaning that it can do multiple different things at the same time. Most theories assume that each word we know is represented by a separate processing unit that has just one job: to assess the likelihood of incoming speech matching that particular word.
In the context(文脈) of the brain, the processing unit that represents a word is likely a pattern of firing activity across a group of neurons in the brain’s cortex(大脳皮質). When we hear the beginning of a word, several thousand such units may become active, because with just the beginning of a word, there are many possible matches. Then, as the word goes on, more and more units register that some vital piece of information is missing and lose activity.
Possibly well before the end of the word, just one firing pattern remains active, corresponding to one word. This is called the ‘recognition point(認識点)’. In the process of honing in on one word, the active units suppress the activity of others, saving vital milliseconds.
Most people can comprehend up to about 8 syllables(音節) per second. Yet, the goal is not only to recognize the word but also to access its stored meaning. The brain accesses many possible meanings at the same time before the word has been fully identified. We know this from studies that show that even upon hearing a word fragment – like ‘cap’ – listeners will start to register multiple possible meanings, like captain or capital, before the full word emerges.
This suggests that every time we hear a word there is a brief explosion of meanings in our minds, and by the recognition point the brain has settled on one interpretation. The recognition process moves more rapidly with a sentence that gives us context than in a random string of words.
Context also helps guide us towards the intended meaning of words with multiple interpretations, like ‘bat’, or ‘crane’, or in cases of homophones(同音異義語) like ‘no’ or ‘know’. For multilingual people, the language they are listening to is another cue, used to eliminate potential words that do not match the language context. So, what about adding completely new words to this system?
Even as adults, we may come across a new word every few days. But if every word is represented as a fine-tuned pattern of activity distributed over many neurons, how do we prevent new words from overwriting old ones? We think that to avoid this problem, new words are initially stored in a part of the brain called the hippocampus(海馬), well away from the main store of words in the cortex(大脳皮質), so they do not share neurons with other words.
Then, over multiple nights of sleep, the new words gradually transfer over and interweave with old ones. Researchers think this gradual acquisition process helps avoid disrupting existing words. So in the daytime, unconscious activity generates explosions of meaning as we chat away. At night, we rest, but our brains are busy integrating new knowledge into the word network.
When we wake up, this process ensures that we are ready for the ever-changing world of language.


